
Introduction: Why Understanding Machine Learning Types Matters More Than Ever
In a world increasingly driven by data, machine learning has quietly become the engine behind many of the technologies we use daily—from recommendation systems on streaming platforms to fraud detection in banking. But while the term “machine learning” is widely used, many learners and professionals struggle to understand its foundational categories and how they differ in real-world applications. If you’re aiming to build a strong base in data science, artificial intelligence, or analytics, understanding the core types of machine learning is not optional—it’s essential.
This article breaks down the major types of machine learning—Supervised Learning, Unsupervised Learning, Semi-Supervised, and Reinforcement Learning—in a structured, detailed, and easy-to-understand way. Whether you’re a student exploring AI, a professional upskilling, or someone curious about how machines learn from data, this guide will help you grasp the concepts deeply and apply them effectively.
1. Supervised Learning: Learning with Labeled Data
What is Supervised Learning?
Supervised learning is one of the most widely used types of machine learning, where the model is trained using labeled datasets. This means that each input data point is paired with a correct output, allowing the algorithm to learn the mapping between inputs and outputs. The goal is to enable the model to make accurate predictions when new, unseen data is introduced.
In simpler terms, supervised learning is like teaching a child using flashcards—each card shows a question and the correct answer, helping the child learn patterns over time.
How It Works
In supervised learning, the algorithm learns by minimizing the difference between predicted outputs and actual outputs. This process is typically achieved through optimization techniques such as gradient descent, where the model adjusts its parameters iteratively.
There are two main categories within supervised learning:
- Regression: Predicting continuous values (e.g., house prices)
- Classification: Predicting discrete labels (e.g., spam vs. non-spam emails)
Examples of Supervised Learning
- Email spam detection
- Predicting stock prices
- Medical diagnosis (e.g., detecting diseases from images)
- Credit scoring systems
Popular Algorithms
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines (SVM)
- Neural Networks
Advantages and Limitations
Supervised learning offers high accuracy when sufficient labeled data is available. However, it requires large amounts of labeled data, which can be time-consuming and expensive to collect. Additionally, it may struggle with unseen patterns if the training data is not diverse enough.
2. Unsupervised Learning: Discovering Hidden Patterns
What is Unsupervised Learning?
Unlike supervised learning, unsupervised learning works with unlabeled data, meaning the model is not given any predefined output. Instead, it explores the data to identify hidden structures, patterns, or relationships on its own.
This type of learning is similar to exploring a new city without a map—you observe patterns, group similar places, and build your own understanding of the environment.
How It Works
Unsupervised learning algorithms attempt to organize data based on similarities and differences. The model identifies inherent structures such as clusters or associations without any guidance.
There are two main techniques:
- Clustering: Grouping similar data points together
- Association: Finding relationships between variables
Examples of Unsupervised Learning
- Customer segmentation in marketing
- Market basket analysis (e.g., “customers who bought X also bought Y”)
- Anomaly detection (e.g., fraud detection)
- Document clustering
Popular Algorithms
- K-Means Clustering
- Hierarchical Clustering
- DBSCAN
- Principal Component Analysis (PCA)
- Apriori Algorithm
Advantages and Limitations
Unsupervised learning is powerful for discovering unknown patterns and insights in data, especially when labeled data is unavailable. However, interpreting the results can be challenging, and there is no clear way to validate accuracy since no ground truth is provided.
3. Semi-Supervised Learning: Bridging the Gap Between Labeled and Unlabeled Data
What is Semi-Supervised Learning?
Semi-supervised learning is a machine learning approach that combines a small amount of labeled data with a large amount of unlabeled data to train models. Unlike supervised learning, which depends entirely on labeled datasets, and unsupervised learning, which works without labels, semi-supervised learning lies in between—leveraging the strengths of both.
This approach is similar to learning a new skill with a few guided lessons (labeled data) and a lot of self-practice (unlabeled data). The initial guidance helps build a foundation, while independent exploration strengthens understanding and improves performance over time.
How It Works
Semi-supervised learning begins by training a model on a limited labeled dataset to learn basic patterns and relationships. Once the model gains an initial understanding, it starts analyzing the unlabeled data to identify underlying structures and similarities.
A common technique used here is pseudo-labeling, where the model predicts labels for the unlabeled data and then uses those predictions as if they were actual labels. The model is then retrained using both real and pseudo-labeled data, improving iteratively.
There are two main strategies:
- Self-Training: The model trains itself by generating and learning from pseudo-labels
- Consistency Learning: The model learns to produce stable predictions even when the input data is slightly modified
Examples of Semi-Supervised Learning
Semi-supervised learning is widely applied in scenarios where labeled data is scarce but raw data is abundant:
- Medical image classification with limited annotated scans
- Email spam detection using a small labeled dataset and large unlabeled inbox data
- Speech recognition systems trained on partially labeled audio
- Text classification using a few labeled documents and large corpora of unlabeled text
- Image recognition in social media platforms
Popular Algorithms and Techniques
Several methods are commonly used in semi-supervised learning, depending on the problem and data:
- Self-Training
- Co-Training
- Label Propagation (Graph-Based Methods)
- Consistency Regularization (e.g., Mean Teacher, FixMatch)
- Semi-Supervised Support Vector Machines (S3VM)
These techniques help models effectively utilize unlabeled data to improve learning outcomes.
Advantages and Limitations
Semi-supervised learning offers a practical solution for modern machine learning challenges by reducing the dependency on large labeled datasets while still achieving strong performance. It is cost-effective, scalable, and capable of improving model accuracy by leveraging additional unlabeled data.
However, it also comes with certain limitations. The model may generate incorrect pseudo-labels, which can lead to error propagation during training. It is also sensitive to assumptions about data distribution and can be more complex to implement compared to traditional methods. Additionally, evaluating performance can be difficult due to the limited availability of labeled data.
4. Reinforcement Learning: Learning Through Interaction
What is Reinforcement Learning?
Reinforcement learning (RL) is a type of machine learning where an agent learns by interacting with an environment and receiving feedback in the form of rewards or penalties. The goal is to maximize cumulative rewards over time by choosing the best actions.
This approach is inspired by behavioral psychology, where learning occurs through trial and error.
How It Works
In reinforcement learning, the system consists of:
- Agent: The learner or decision-maker
- Environment: The system the agent interacts with
- Actions: Choices made by the agent
- Rewards: Feedback received after an action
The agent continuously improves its strategy (policy) based on rewards received from the environment.
Examples of Reinforcement Learning
- Game playing (e.g., chess, Go, video games)
- Self-driving cars
- Robotics
- Recommendation systems with dynamic feedback
- Stock trading strategies
Popular Algorithms
- Q-Learning
- Deep Q Networks (DQN)
- Policy Gradient Methods
- Actor-Critic Models
Advantages and Limitations
Reinforcement learning is highly effective for complex decision-making tasks and dynamic environments. However, it requires significant computational resources and time for training. It can also be difficult to design reward systems that lead to desired outcomes.
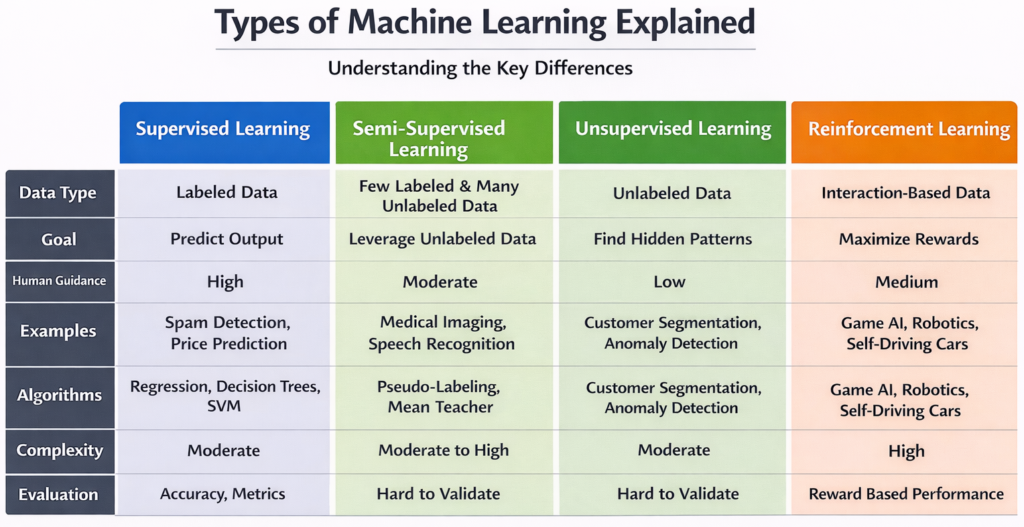
Comparison of Machine Learning Types
| Feature | Supervised Learning | Semi-Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|---|
| Data Type | Labeled Data | Few Labeled & Many Unlabeled Data | Unlabeled Data | Interaction-Based Data |
| Goal | Predict Output | Leverage Unlabeled Data | Find Hidden Patterns | Maximize Rewards |
| Human Guidance | High | Moderate | Low | Medium |
| Examples | Spam Detection, Price Prediction | Medical Imaging, Speech Recognition | Customer Segmentation, Anomaly Detection | Game AI, Robotics, Self-Driving Cars |
| Algorithms | Regression, Decision Trees, SVM | Pseudo-Labeling, Mean Teacher | K-Means, PCA, Apriori | Q-Learning, Deep Q-Networks |
| Complexity | Moderate | Moderate to High | Moderate | High |
| Evaluation | Accuracy, Metrics | Hard to Validate | Hard to Validate | Reward-Based Performance |
When to Use Each Type of Machine Learning
Choosing the right type of machine learning depends on the nature of your data and the problem you are trying to solve.
- Use Supervised Learning when you have labeled data and want to make predictions.
- Use Unsupervised Learning when you want to explore data and uncover hidden insights.
- Use Semi-Supervised Learning when you have a few labeled and a large amount of unlabeled data and want to improve model performance without the high cost of labeling.
- Use Reinforcement Learning when the problem involves sequential decisions and dynamic environments.
Understanding these distinctions is critical for designing efficient machine learning solutions and improving model performance.
Real-World Applications Across Industries
Machine learning types are not just theoretical concepts—they power real-world innovations across industries:
- Healthcare: Disease prediction (supervised), patient clustering (unsupervised)
- Finance: Fraud detection (unsupervised), credit scoring (supervised)
- E-commerce: Product recommendations (reinforcement learning)
- Marketing: Customer segmentation (unsupervised), campaign prediction (supervised)
- Autonomous Systems: Self-driving cars (reinforcement learning)
These applications demonstrate how each type of learning serves a unique purpose and contributes to solving complex problems.
Conclusion: Building a Strong Foundation in Machine Learning
Understanding the types of machine learning—supervised, unsupervised, semi-supervised, and reinforcement learning—is fundamental for anyone entering the field of data science or AI. Each type offers unique strengths, addresses different kinds of problems, and requires different approaches to data and modeling.
By mastering these core concepts, you not only gain clarity but also position yourself to build more effective and intelligent systems. As machine learning continues to evolve, this foundational knowledge will remain essential in navigating more advanced topics and real-world applications.
Also Read: Data Collection for Machine Learning