
Introduction: How AI Learns from Limited Labeled Data (And Why It Matters Today)
In a world overflowing with data, one paradox continues to challenge data scientists and organizations alike: while massive amounts of data are generated every second, only a tiny fraction of it is labeled and ready for machine learning. Labeling data is expensive, time-consuming, and often requires domain expertise. So how do modern AI systems still manage to learn effectively? The answer lies in semi-supervised learning—a powerful approach that bridges the gap between supervised and unsupervised learning.
By leveraging both labeled and unlabeled data, semi-supervised learning unlocks new possibilities in scalability, efficiency, and performance. Whether you’re a student exploring machine learning or a professional building real-world models, understanding this concept can fundamentally change how you approach data problems.
What is Semi-Supervised Learning?
Semi-supervised learning is a machine learning approach that uses a small amount of labeled data combined with a large amount of unlabeled data to train models. Unlike supervised learning, which relies entirely on labeled datasets, or unsupervised learning, which works without labels, semi-supervised learning strikes a balance between the two.
The core idea is simple: even though only a portion of the data is labeled, the structure and patterns present in the unlabeled data can still provide valuable insights. By incorporating this additional information, models can generalize better and achieve higher accuracy than using labeled data alone.
This approach is particularly useful in domains where labeling data is costly, such as medical imaging, natural language processing, and speech recognition.
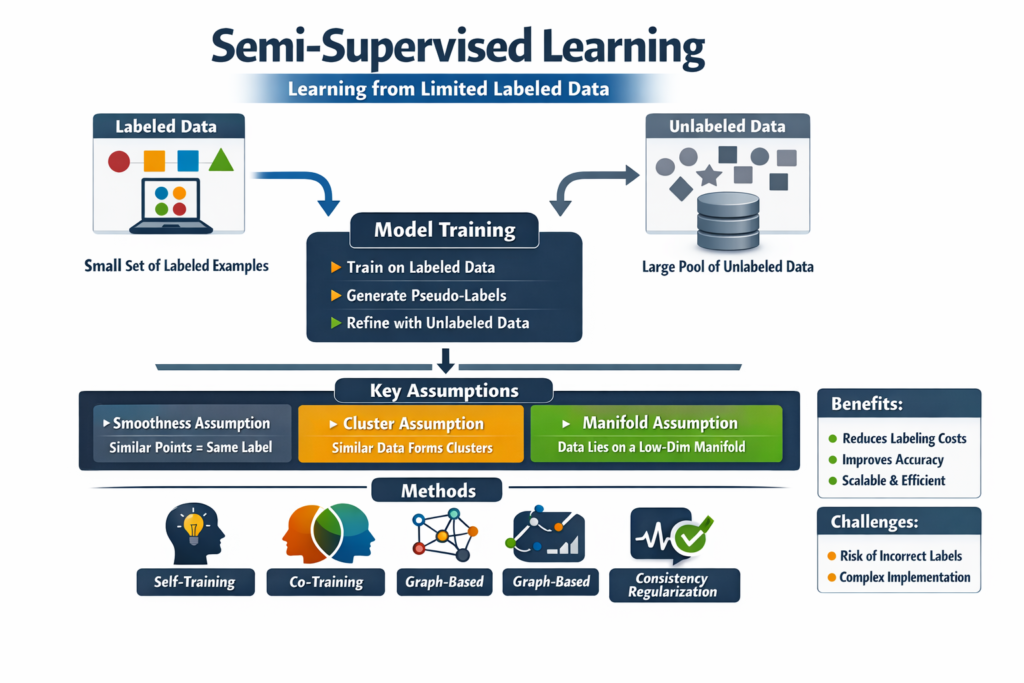
Why Semi-Supervised Learning is Important
One of the biggest challenges in machine learning is the data labeling bottleneck. Organizations often have access to vast amounts of raw data but lack the resources to annotate it. Semi-supervised learning addresses this issue by making efficient use of available data.
It reduces dependency on labeled data while still maintaining strong predictive performance. This makes it highly practical for real-world applications where acquiring labeled datasets is not feasible at scale.
Additionally, semi-supervised learning improves model robustness by exposing it to more diverse data distributions, helping it perform better on unseen data.
How Semi-Supervised Learning Works
At its core, semi-supervised learning works by combining two key processes: learning from labeled examples and extracting patterns from unlabeled data.
Step 1: Train on Labeled Data
The process begins with a small labeled dataset. The model learns initial patterns and relationships between input features and target labels.
Step 2: Leverage Unlabeled Data
Next, the model uses the unlabeled data to refine its understanding. It identifies clusters, distributions, and structures that exist naturally in the data.
Step 3: Generate Pseudo-Labels
One common technique is pseudo-labeling, where the model predicts labels for unlabeled data and treats them as if they were true labels. These pseudo-labeled examples are then used to retrain the model.
Step 4: Iterative Improvement
The model iteratively updates itself by combining real labeled data and pseudo-labeled data, improving its performance over time.
This cycle continues until the model reaches a satisfactory level of accuracy.
Key Assumptions Behind Semi-Supervised Learning
Semi-supervised learning relies on a few important assumptions to work effectively:
1. Smoothness Assumption
If two data points are close to each other, they are likely to share the same label. This allows the model to propagate labels to nearby unlabeled points.
2. Cluster Assumption
Data tends to form clusters, and points within the same cluster usually belong to the same class. The model uses these clusters to infer labels.
3. Manifold Assumption
High-dimensional data often lies on a lower-dimensional manifold. Semi-supervised learning exploits this structure to improve learning efficiency.
These assumptions help the model make meaningful use of unlabeled data.
Popular Techniques in Semi-Supervised Learning
Several techniques are commonly used to implement semi-supervised learning:
Self-Training
In this approach, the model trains itself by generating pseudo-labels for unlabeled data and iteratively improving.
Co-Training
Two or more models are trained simultaneously on different views of the data. Each model helps label data for the others.
Graph-Based Methods
Data points are represented as nodes in a graph, and labels are propagated through connections between similar points.
Consistency Regularization
The model is trained to produce consistent predictions even when the input data is slightly perturbed. This improves generalization.
Each method has its strengths depending on the dataset and application.
Real-World Applications of Semi-Supervised Learning
Semi-supervised learning is widely used in various industries due to its efficiency:
Healthcare
In medical imaging, labeled data is scarce because it requires expert annotation. Semi-supervised learning helps detect diseases using limited labeled scans.
Natural Language Processing
Tasks like sentiment analysis and text classification benefit from large volumes of unlabeled text data.
Computer Vision
Image recognition systems use semi-supervised learning to improve accuracy without requiring extensive labeled datasets.
Speech Recognition
Voice-based systems leverage unlabeled audio data to enhance performance.
These applications demonstrate how semi-supervised learning solves real-world challenges.
Comparison: Supervised vs Unsupervised vs Semi-Supervised Learning
| Feature | Supervised Learning | Unsupervised Learning | Semi-Supervised Learning |
|---|---|---|---|
| Data Requirement | Fully labeled data | No labeled data | Few labeled + many unlabeled |
| Cost | High (labeling required) | Low | Moderate |
| Accuracy | High (if enough data) | Lower | Often high |
| Complexity | Moderate | High | High |
| Use Case | Classification, Regression | Clustering, Association | Hybrid tasks |
This comparison highlights why semi-supervised learning is often considered a practical middle ground.
Advantages of Semi-Supervised Learning
Semi-supervised learning offers several significant benefits:
Reduced Labeling Cost
It minimizes the need for expensive manual labeling by utilizing unlabeled data.
Improved Accuracy
By leveraging more data, models can achieve better performance compared to purely supervised methods with limited data.
Scalability
It works well with large datasets, making it suitable for modern data-driven applications.
Better Generalization
Exposure to diverse data improves the model’s ability to handle unseen scenarios.
Challenges and Limitations
Despite its advantages, semi-supervised learning is not without challenges:
Risk of Incorrect Pseudo-Labels
If the model generates incorrect labels, it can reinforce errors during training.
Model Sensitivity
Performance depends heavily on assumptions about data distribution.
Complex Implementation
Designing effective semi-supervised systems can be more complex than traditional approaches.
Evaluation Difficulty
Since not all data is labeled, evaluating model performance can be challenging.
Understanding these limitations is crucial for practical implementation.
Best Practices for Using Semi-Supervised Learning
To fully leverage the potential of semi-supervised learning while minimizing its risks, it is important to follow a set of best practices that guide the development and deployment of models.
Start with a High-Quality Labeled Dataset
Even though semi-supervised learning reduces the need for large labeled datasets, the quality of the initial labeled data remains critical. A small but accurate and representative labeled dataset provides a strong foundation for the model to learn initial patterns. Poor-quality labels can mislead the model from the beginning, affecting the entire training process.
Use Confidence Thresholds for Pseudo-Labels
When generating pseudo-labels, it is essential to apply confidence thresholds to ensure that only reliable predictions are used for further training. By filtering out low-confidence predictions, you can reduce the risk of introducing noise into the dataset and prevent error propagation.
Regular Validation and Monitoring
Consistently validating the model using a separate labeled validation set helps track performance and detect issues early. Monitoring metrics such as accuracy, precision, recall, or loss over time allows you to identify overfitting, underfitting, or instability in the training process.
Experiment with Multiple Techniques
Different semi-supervised learning techniques work better for different types of data and problems. Experimenting with approaches such as self-training, co-training, or consistency regularization can help identify the most effective method for your specific use case. Combining multiple techniques may also lead to improved results.
Monitor for Overfitting and Error Propagation
Since semi-supervised learning involves iterative training, there is a risk of the model overfitting to incorrect patterns or reinforcing errors. Regular monitoring, early stopping, and periodic retraining with updated labeled data can help mitigate these risks and maintain model performance.
Future of Semi-Supervised Learning
As data continues to grow exponentially, semi-supervised learning is becoming increasingly relevant. Advances in deep learning and AI are making it easier to integrate unlabeled data into training pipelines.
Emerging techniques such as self-supervised learning and foundation models are further expanding the boundaries of what can be achieved with minimal labeled data. In the future, we can expect semi-supervised learning to play a central role in building scalable, efficient, and intelligent systems.