
Introduction: Why Your Model Fails Before It Even Starts
Most machine learning failures don’t happen at the modeling stage—they happen much earlier, silently, during data preparation. You can build the most advanced model with cutting-edge algorithms, but if your data is inconsistent, incomplete, or duplicated, your results will be unreliable at best and misleading at worst. Data cleaning is not just a preliminary step; it is the foundation upon which every successful machine learning system is built.
In real-world scenarios, raw data is messy. It contains missing values, duplicate entries, inconsistent formats, and noise. Without proper preprocessing, machine learning models learn patterns that do not reflect reality. This article explores essential data cleaning techniques—data preprocessing, duplicate removal, and null handling—while also providing practical examples and structured comparisons to help you apply them effectively.
What is Data Cleaning in Machine Learning?
Data cleaning is the process of detecting, correcting, or removing inaccurate, incomplete, or irrelevant data from a dataset. It ensures that the data collected for machine learning and fed into the machine learning algorithms is reliable, consistent, and meaningful.
Key Objectives of Data Cleaning
- Improve data quality and integrity
- Reduce noise and inconsistencies
- Enhance model accuracy and performance
- Prevent biased or misleading predictions
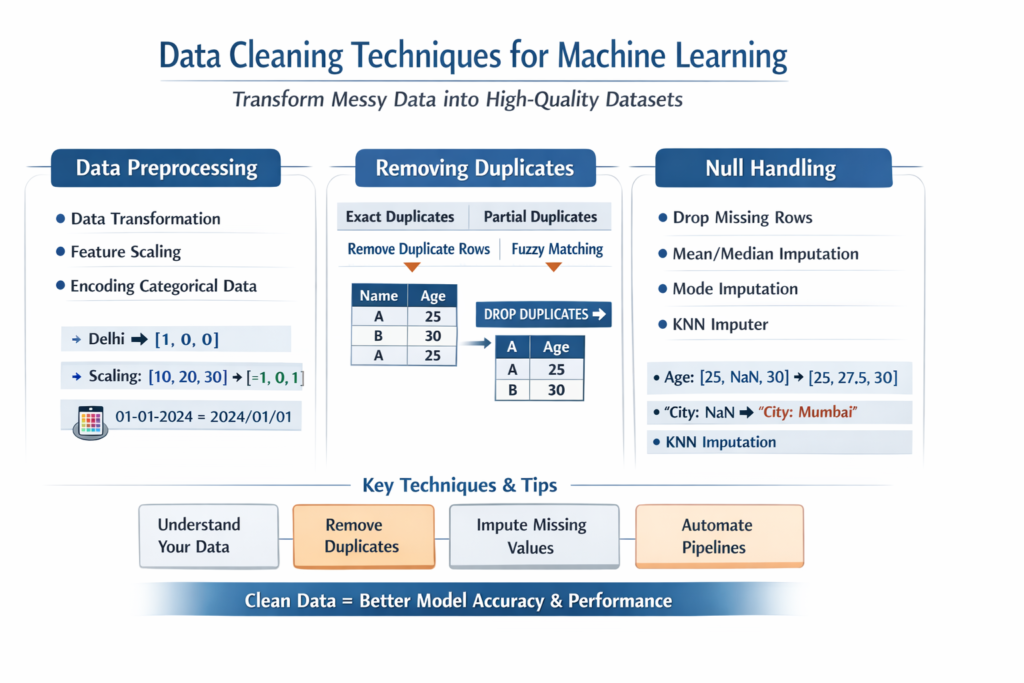
1. Data Preprocessing: Preparing Data for Machine Learning
Data preprocessing is a broader step that includes transforming raw data into a structured and usable format. It encompasses cleaning, normalization, encoding, and feature transformation.
Key Steps in Data Preprocessing
1.1 Data Transformation
Transforming data into suitable formats is crucial. This includes:
- Converting categorical data into numerical values
- Standardizing date formats
- Scaling numerical features
Example (Python – Encoding Categorical Data):
import pandas as pddf = pd.DataFrame({
'City': ['Delhi', 'Mumbai', 'Chennai']
})encoded_df = pd.get_dummies(df, columns=['City'])
print(encoded_df)
1.2 Feature Scaling
Machine learning algorithms perform better when features are on a similar scale.
Example (Standardization):
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
scaled_data = scaler.fit_transform([[10], [20], [30]])
print(scaled_data)
1.3 Handling Inconsistent Data Formats
Inconsistent formats can distort analysis. For example:
- “01-01-2024” vs “2024/01/01”
- “Male” vs “M”
Solution:
df['Gender'] = df['Gender'].replace({'M': 'Male', 'F': 'Female'})
2. Removing Duplicates: Eliminating Redundant Data
Duplicate data occurs when the same record appears multiple times in a dataset. This can lead to:
- Biased model training
- Incorrect statistical analysis
- Increased computational cost
Why Duplicate Removal Matters
Duplicates can artificially inflate the importance of certain patterns, causing the model to overfit or learn incorrect relationships.
Example: Removing Duplicates in Python
import pandas as pddf = pd.DataFrame({
'Name': ['A', 'B', 'A'],
'Age': [25, 30, 25]
})df_cleaned = df.drop_duplicates()
print(df_cleaned)
Types of Duplicate Handling
| Type of Duplicate | Description | Solution |
|---|---|---|
| Exact Duplicates | Identical rows | Remove using drop_duplicates() |
| Partial Duplicates | Similar but not identical | Use fuzzy matching |
| Key-based Duplicates | Same primary key with different attributes | Keep latest or aggregated record |
Advanced Duplicate Handling (Subset-Based)
df.drop_duplicates(subset=['Name'], keep='last', inplace=True)
This keeps the last occurrence of each unique name.
3. Null Handling: Managing Missing Values
Missing values are one of the most common issues in real-world datasets. They can arise due to:
- Data entry errors
- Sensor failures
- Incomplete surveys
Why Null Handling is Critical
Ignoring missing values can:
- Break algorithms
- Reduce model accuracy
- Introduce bias
Types of Missing Data
| Type | Description |
|---|---|
| MCAR (Missing Completely at Random) | No relationship with any variable |
| MAR (Missing at Random) | Related to other observed variables |
| MNAR (Missing Not at Random) | Related to the missing value itself |
Common Techniques for Handling Null Values
3.1 Removing Missing Values
Useful when missing data is minimal.
df.dropna(inplace=True)
3.2 Imputation Techniques
Mean/Median Imputation
df['Age'].fillna(df['Age'].mean(), inplace=True)
Mode Imputation (Categorical Data)
df['City'].fillna(df['City'].mode()[0], inplace=True)
3.3 Forward/Backward Fill
Useful for time-series data.
df.fillna(method='ffill', inplace=True)
3.4 Advanced Imputation (Using ML Models)
from sklearn.impute import KNNImputerimputer = KNNImputer(n_neighbors=2)
df_imputed = imputer.fit_transform(df)
Comparison of Null Handling Techniques
| Method | Best Use Case | Pros | Cons |
|---|---|---|---|
| Drop Rows | Small missing data | Simple, fast | Data loss |
| Mean/Median | Numerical data | Easy, efficient | Ignores relationships |
| Mode | Categorical data | Maintains category | May introduce bias |
| Forward Fill | Time series | Maintains sequence | Not always accurate |
| KNN Imputation | Complex datasets | More accurate | Computationally expensive |
Best Practices for Data Cleaning
Data cleaning is not just about fixing errors—it’s about making informed decisions that directly impact model performance and reliability. The following best practices are widely used in real-world machine learning workflows and are critical for building robust systems.
1. Understand Your Data First (Exploratory Data Analysis – EDA)
Before you clean anything, you must understand what you’re working with. Jumping straight into cleaning without analyzing the dataset often leads to incorrect assumptions and poor decisions.
Why This Matters
Every dataset has its own structure, patterns, and issues. Without understanding:
- You might remove important outliers that actually represent real-world events
- You could misinterpret missing values
- You may apply wrong transformations
What to Analyze in EDA
- Data types (numerical, categorical, datetime)
- Distribution of values
- Missing values percentage
- Duplicate entries
- Outliers
Example (Basic EDA in Python)
import pandas as pddf = pd.read_csv("data.csv")# Overview of data
print(df.info())# Summary statistics
print(df.describe())# Check missing values
print(df.isnull().sum())# Check duplicates
print(df.duplicated().sum())
Key Insight
EDA helps you answer questions like:
- Is missing data random or systematic?
- Are duplicates errors or valid repeated events?
- Do extreme values represent noise or real scenarios?
2. Avoid Blind Deletion
Deleting data might seem like the easiest solution, but it is often the most dangerous one if done without analysis.
Why Blind Deletion is Risky
- You may lose critical patterns in the data
- It can introduce bias into the dataset
- It reduces the dataset size, affecting model training
Example Problem
If you remove all rows with missing income values in a financial dataset, you might unintentionally remove data from a specific demographic group, leading to biased predictions.
Better Alternatives
Instead of deleting:
- Impute missing values (mean, median, ML-based)
- Use domain knowledge to decide
- Flag missing values as a separate category
Example (Conditional Deletion)
# Remove only if missing values exceed threshold
threshold = 0.5
df = df[df.isnull().mean(axis=1) < threshold]
Comparison: Blind Deletion vs Smart Handling
| Approach | Description | Risk Level | Recommended |
|---|---|---|---|
| Blind Deletion | Remove all problematic rows | High | No |
| Conditional Drop | Remove based on thresholds | Medium | Yes |
| Imputation | Fill missing values intelligently | Low | Yes |
3. Maintain Data Integrity
Data integrity means preserving the original meaning and relationships within the dataset while cleaning or transforming it.
Why This is Critical
If transformations distort the data:
- Models learn incorrect patterns
- Predictions become unreliable
- Business decisions may be wrong
Common Mistakes
- Converting categorical values incorrectly
- Scaling data without understanding context
- Incorrect date conversions
- Mixing units (e.g., kg vs pounds)
Example: Wrong vs Correct Transformation
Wrong Approach:
# Encoding without understanding categories
df['Size'] = df['Size'].map({'Small': 1, 'Medium': 2, 'Large': 3})
If “Size” has no ordinal relationship, this introduces false hierarchy.
Correct Approach:
df = pd.get_dummies(df, columns=['Size'])
Another Example: Unit Consistency
If some values are in meters and others in centimeters:
# Convert all to meters
df['height'] = df['height'] / 100
Key Principle
Always ask:
“Does this transformation preserve the real-world meaning of the data?”
4. Automate Cleaning Pipelines
Manual data cleaning is not scalable, especially in production systems. Automation ensures consistency, reproducibility, and efficiency.
Why Automation is Important
- Reduces human error
- Ensures consistent preprocessing across datasets
- Saves time in repeated workflows
- Essential for deployment in ML pipelines
What is a Data Pipeline?
A pipeline is a sequence of steps applied to data in a fixed order:
- Missing value handling
- Encoding
- Scaling
- Feature selection
Example: Pipeline in Python (Scikit-learn)
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScalerpipeline = Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])cleaned_data = pipeline.fit_transform(df)
Benefits of Pipelines
| Benefit | Explanation |
|---|---|
| Consistency | Same steps applied every time |
| Reproducibility | Easy to replicate results |
| Scalability | Works for large datasets |
| Integration | Easily integrates with ML models |
- EDA first ensures you make informed decisions
- Avoiding blind deletion protects valuable data
- Maintaining integrity preserves real-world meaning
- Automating pipelines ensures scalability and consistency
Real-World Impact of Data Cleaning
In industries like healthcare, finance, and e-commerce, data cleaning directly affects decision-making. For example:
- In fraud detection, duplicate transactions can lead to false alarms
- In healthcare, missing patient data can result in incorrect diagnoses
- In recommendation systems, inconsistent data leads to poor personalization
Conclusion: Clean Data, Better Models
Data cleaning is not a one-time task but an iterative process that evolves with your dataset and problem statement. Investing time in preprocessing, removing duplicates, and handling null values ensures that your machine learning models are not just accurate but also reliable and trustworthy.