
Introduction: Way to Faster, Smarter, and More Accurate Models
In the race to build high-performing machine learning models, most practitioners obsess over algorithms, hyperparameters, and architectures. Yet, one of the most powerful and often overlooked levers lies much earlier in the pipeline: feature selection methods. Imagine training a model on thousands of variables, only to discover that a small subset was responsible for most of the predictive power. Not only does this realization save time and computational cost, but it also transforms how we think about data quality and model interpretability. Feature selection is not just a preprocessing step—it is a strategic decision that can determine whether your model succeeds or fails in real-world scenarios.
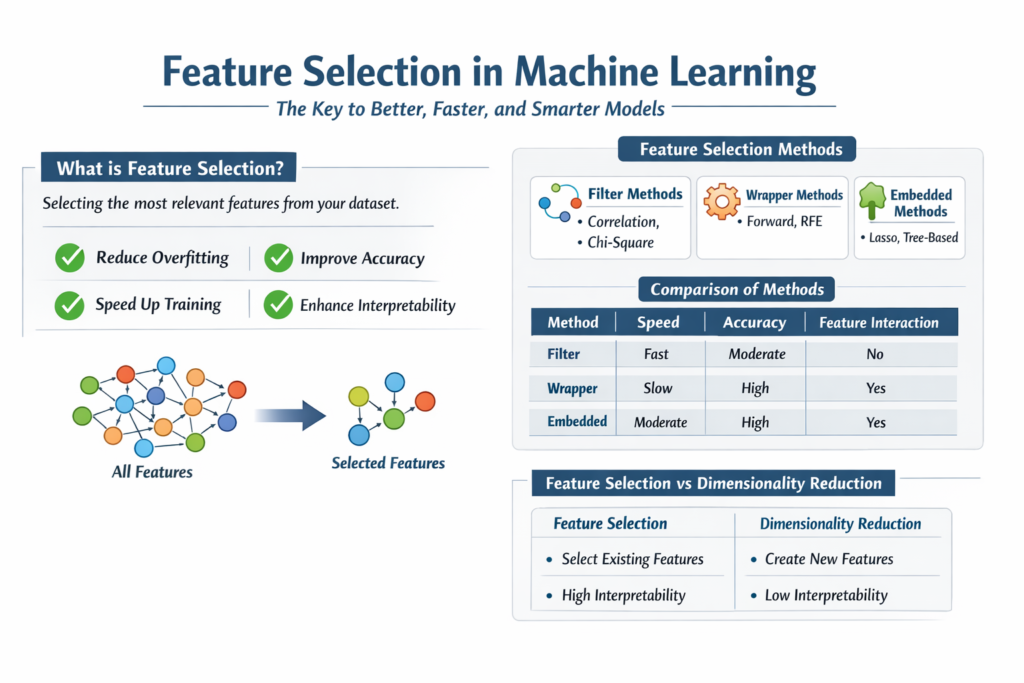
What is Feature Selection in Machine Learning?
Feature selection is the process of identifying and selecting a subset of relevant input variables (features) from a dataset that contribute the most to the predictive performance of a machine learning model. Instead of feeding all available features into the model, feature selection filters out redundant, irrelevant, or noisy variables.
This process is crucial because real-world datasets often contain unnecessary information. These irrelevant features can confuse the model, increase complexity, and degrade performance. By focusing only on meaningful features, models become more efficient and easier to interpret.
Feature selection differs from feature extraction. While feature extraction transforms existing features into new ones (e.g., PCA), feature selection simply chooses a subset of the original features without modifying them.
Why Feature Selection Improves Machine Learning Performance
1. Reduces Overfitting
When models are trained on too many irrelevant features, they tend to memorize noise instead of learning patterns. Feature selection eliminates such noise, helping models generalize better on unseen data.
2. Improves Model Accuracy
By removing irrelevant variables, the model focuses only on the most impactful features. This often leads to better predictive performance and more reliable outcomes.
3. Enhances Model Interpretability
A model with fewer features is easier to understand and explain. This is particularly important in domains like healthcare, finance, and policymaking.
4. Reduces Training Time
Fewer features mean less computation. This speeds up training, especially for large datasets and complex models.
5. Mitigates the Curse of Dimensionality
High-dimensional datasets can lead to sparse data distributions. Feature selection reduces dimensionality, making patterns easier to detect.
Types of Feature Selection Methods
Feature selection techniques are broadly classified into three main categories:
1. Filter Methods
Filter methods evaluate features independently of any machine learning algorithm. They rely on statistical measures to determine the relationship between features and the target variable.
These methods are fast and computationally efficient but may ignore feature interactions.
Common techniques include:
- Correlation coefficient
- Chi-square test
- Mutual information
- Variance threshold
Example (Python):
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.datasets import load_irisX, y = load_iris(return_X_y=True)selector = SelectKBest(score_func=chi2, k=2)
X_new = selector.fit_transform(X, y)print(X_new.shape)
In this example, the top two features are selected based on the chi-square test, which measures dependency between variables.
2. Wrapper Methods
Wrapper methods evaluate subsets of features by actually training a model. They use predictive performance as a criterion to select the best feature subset.
These methods are more accurate than filter methods but computationally expensive.
Common techniques include:
- Forward Selection
- Backward Elimination
- Recursive Feature Elimination (RFE)
Example (Python):
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_irisX, y = load_iris(return_X_y=True)model = LogisticRegression(max_iter=200)
rfe = RFE(model, n_features_to_select=2)X_new = rfe.fit_transform(X, y)print(X_new.shape)
Here, RFE recursively removes the least important features until the desired number is reached.
3. Embedded Methods
Embedded methods perform feature selection as part of the model training process. They combine the advantages of both filter and wrapper methods.
These methods are efficient and often provide a good balance between performance and computational cost.
Common techniques include:
- Lasso (L1 regularization)
- Ridge (L2 regularization)
- Tree-based feature importance
Example (Python):
from sklearn.linear_model import Lasso
from sklearn.datasets import load_diabetesX, y = load_diabetes(return_X_y=True)lasso = Lasso(alpha=0.1)
lasso.fit(X, y)selected_features = X[:, lasso.coef_ != 0]print(selected_features.shape)
Lasso shrinks some coefficients to zero, effectively removing less important features.
Comparison of Feature Selection Methods
| Method Type | Speed | Accuracy | Considers Feature Interaction | Use Case |
|---|---|---|---|---|
| Filter | Very Fast | Moderate | No | Large datasets, quick preprocessing |
| Wrapper | Slow | High | Yes | Small datasets, high accuracy needed |
| Embedded | Moderate | High | Yes | Balanced approach |
Popular Feature Selection Techniques Explained
1. Correlation-Based Selection
This method selects features that have a high correlation with the target variable but low correlation with each other. It helps avoid redundancy and multicollinearity.
2. Variance Threshold
Features with very low variance do not contribute much to prediction. Removing them simplifies the dataset without losing meaningful information.
3. Mutual Information
This measures how much information one variable provides about another. It captures non-linear relationships, making it more powerful than simple correlation.
4. Recursive Feature Elimination (RFE)
RFE iteratively removes the least important features based on model weights. It is widely used for its effectiveness in selecting optimal subsets.
5. L1 Regularization (Lasso)
Lasso adds a penalty to the model that forces less important feature coefficients to become zero, automatically performing feature selection.
When Should You Use Feature Selection Methods?
Feature selection is especially useful in the following scenarios:
- High-dimensional datasets (e.g., genomics, text data)
- When model interpretability is critical
- Limited computational resources
- Presence of noisy or redundant features
- Improving model performance and generalization
Feature Selection vs Dimensionality Reduction
| Aspect | Feature Selection | Dimensionality Reduction |
|---|---|---|
| Approach | Selects existing features | Creates new features |
| Interpretability | High | Low |
| Data Transformation | No | Yes |
| Example Techniques | RFE, Chi-square, Lasso | PCA, t-SNE |
Feature selection preserves the original meaning of variables, making it more suitable for explainable models.
Best Practices for Feature Selection Methods
1. Understand Your Data
Before applying any technique, analyze feature distributions, correlations, and domain relevance.
2. Avoid Data Leakage
Perform feature selection only on training data, not on the entire dataset.
3. Combine Methods
Using a mix of filter and embedded methods often yields better results.
4. Validate Performance
Always evaluate model performance before and after feature selection to ensure improvements.
5. Use Domain Knowledge
Expert insights can help identify important features that algorithms might overlook.
Real-World Example: Feature Selection in Action
Consider a telecom churn prediction model with 50 features. After applying feature selection methods:
- Only 15 features are retained
- Model accuracy improves by 8%
- Training time reduces by 40%
- Model becomes easier to explain to stakeholders
This demonstrates how feature selection directly impacts business outcomes.
Conclusion: Why Feature Selection is a Must-Have Skill
Feature selection methods are not just a technical step—it is a strategic advantage. In a world where data is abundant but attention is limited, selecting the right features allows models to focus on what truly matters. Whether you are a student learning machine learning, a data scientist optimizing models, or a business analyst seeking insights, mastering feature selection can significantly elevate your work.