
Introduction: Why Your Neural Network Is Useless Without Activation Functions
Imagine building a powerful neural network with multiple layers, thousands of parameters, and vast data—only to realize it behaves like a simple linear model. That is exactly what happens when activation functions are missing. Activation functions are not just a technical detail; they are the mathematical core that allows neural networks to learn complex patterns, make intelligent decisions, and power modern AI systems like image recognition, chatbots, and recommendation engines.
In this detailed guide, you will explore what activation functions are, why they are essential, where they are used, and how different types compare in real-world scenarios. This article will give you a strong conceptual and practical understanding of activation functions in neural networks.
What Are Activation Functions in Neural Networks?
An activation function is a mathematical function applied to the output of a neuron in a neural network. It determines whether a neuron should be activated (i.e., pass its signal forward) based on the input it receives.
In simpler terms, activation functions introduce non-linearity into the model. Without them, no matter how many layers your neural network has, it would behave like a linear regression model.
Mathematically, a neuron computes:
Then applies an activation function:
Where:
- z = weighted sum
- f(z) = activation function
- a = output of the neuron
This transformation is what allows neural networks to model complex relationships such as images, speech, and language.
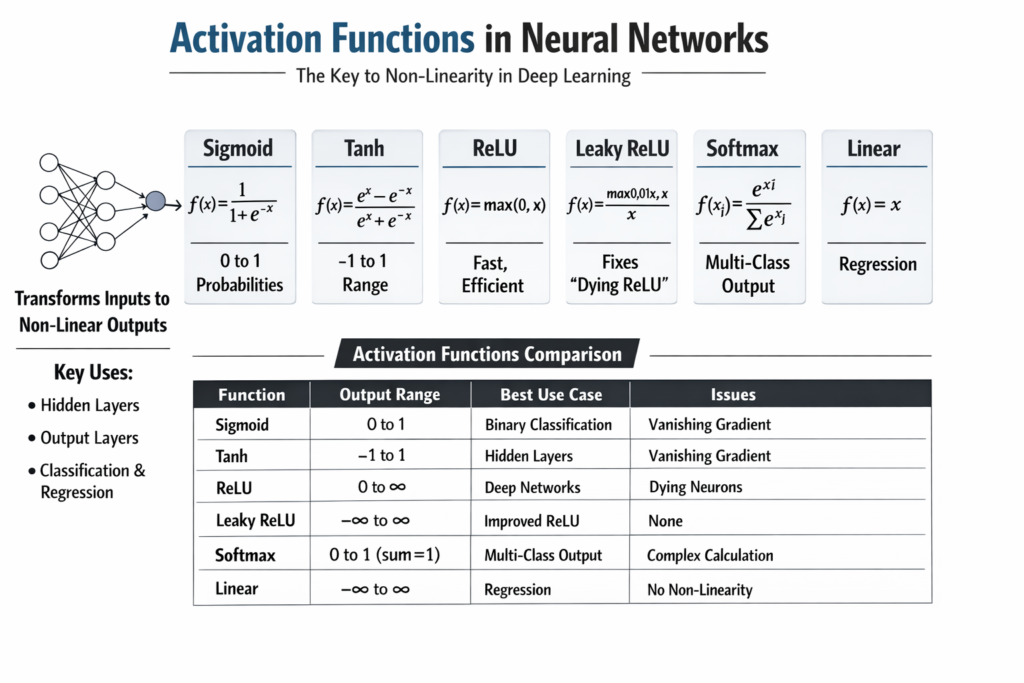
Why Activation Functions Are Important
Activation functions play several critical roles in neural networks:
1. Introducing Non-Linearity
Real-world data is rarely linear. Activation functions enable neural networks to capture non-linear patterns, which are essential for tasks like image classification and natural language processing.
2. Enabling Deep Learning
Without activation functions, stacking multiple layers would not increase the model’s learning capacity. Activation functions make deep architectures meaningful.
3. Controlling Output Range
Some activation functions constrain outputs within a specific range (e.g., 0 to 1), making them suitable for probability predictions.
4. Improving Gradient Flow
Certain activation functions help in stabilizing training and avoiding issues like vanishing gradients.
Where Are Activation Functions Used?
Activation functions are used in every layer of a neural network except the input layer. Their usage varies depending on the task:
Hidden Layers
Used to learn complex patterns and features from data. Common choices:
- ReLU
- Leaky ReLU
- Tanh
Output Layer
Depends on the type of problem:
- Binary classification → Sigmoid
- Multi-class classification → Softmax
- Regression → Linear (no activation or identity function)
Types of Activation Functions Explained
1. Sigmoid Activation Function
The sigmoid function maps input values to a range between 0 and 1.
Key Features:
- Smooth and differentiable
- Outputs interpreted as probabilities
Limitations:
- Vanishing gradient problem
- Not zero-centered
Use Case:
- Binary classification problems
2. Tanh (Hyperbolic Tangent)
The tanh function outputs values between -1 and 1.
Key Features:
- Zero-centered output
- Stronger gradients than sigmoid
Limitations:
- Still suffers from vanishing gradients
Use Case:
- Hidden layers in smaller networks
3. ReLU (Rectified Linear Unit)
Key Features:
- Computationally efficient
- Avoids vanishing gradient (partially)
Limitations:
- “Dying ReLU” problem (neurons stop learning if output becomes 0)
Use Case:
- Most commonly used in hidden layers of deep networks
4. Leaky ReLU
Key Features:
- Solves dying ReLU issue
- Allows small gradient for negative inputs
Use Case:
- Deep networks where ReLU fails
5. Softmax Function
Used for multi-class classification.
Key Features:
- Converts outputs into probabilities
- Sum of outputs = 1
Use Case:
- Final layer in multi-class classification
6. Linear Activation Function
Key Features:
- No transformation applied
Use Case:
- Regression problems
Comparison of Activation Functions
| Activation Function | Output Range | Advantages | Disadvantages | Best Use Case |
|---|---|---|---|---|
| Sigmoid | (0, 1) | Probabilistic output | Vanishing gradient | Binary classification |
| Tanh | (-1, 1) | Zero-centered | Vanishing gradient | Hidden layers |
| ReLU | [0, ∞) | Fast, efficient | Dying neurons | Deep networks |
| Leaky ReLU | (-∞, ∞) | Prevents dead neurons | Slight complexity | Improved ReLU |
| Softmax | (0, 1) sum=1 | Multi-class probabilities | Computationally expensive | Multi-class classification |
| Linear | (-∞, ∞) | Simple | No non-linearity | Regression |
Code Example: Using Activation Functions in Python (Keras)
Here is a simple example demonstrating activation functions in a neural network using TensorFlow/Keras:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# Create model
model = Sequential()# Input + Hidden Layer with ReLU
model.add(Dense(64, activation='relu', input_shape=(10,)))# Hidden Layer with Tanh
model.add(Dense(32, activation='tanh'))# Output Layer with Sigmoid (Binary Classification)
model.add(Dense(1, activation='sigmoid'))# Compile model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])model.summary()
This example shows how different activation functions are used across layers depending on their purpose.
How to Choose the Right Activation Function
Choosing the correct activation function depends on your problem:
For Hidden Layers
- Start with ReLU
- Use Leaky ReLU if dead neurons occur
For Output Layers
- Sigmoid → Binary classification
- Softmax → Multi-class classification
- Linear → Regression
For Deep Networks
- Prefer ReLU variants to avoid gradient issues
Common Problems Related to Activation Functions
1. Vanishing Gradient Problem
Occurs when gradients become too small, slowing learning. Common in sigmoid and tanh.
2. Exploding Gradient Problem
Gradients become too large, causing instability.
3. Dying ReLU Problem
Neurons stop updating when output is always zero.
Real-World Applications of Activation Functions
Activation functions are used in:
- Image recognition systems (CNNs use ReLU)
- Natural language processing models
- Speech recognition
- Recommendation systems
- Fraud detection models
Without activation functions, these systems would fail to capture complex patterns in data.
Conclusion: The Silent Power Behind Neural Networks
Activation functions are the backbone of neural networks, transforming simple linear computations into powerful learning systems capable of modeling real-world complexity. Understanding their behavior, strengths, and limitations is essential for building efficient and accurate machine learning models.
Whether you are designing a simple classifier or a deep learning architecture, the choice of activation function can significantly impact performance. By mastering these functions, you take a crucial step toward becoming proficient in AI and deep learning.