
Introduction: A Deep Dive Into the Hidden Mechanics Behind Machine Intelligence
Artificial Intelligence feels almost magical from the outside—recommendations that seem to read your mind, chatbots that respond like humans, and self-driving systems that detect objects with superhuman precision. But behind this apparent magic lies a structured, methodical learning process. AI systems do not wake up one day knowing how to perform tasks—they learn, layer by layer, from vast amounts of data, refining their understanding through millions of tiny adjustments. Understanding how AI systems learn gives you a powerful perspective into the future of technology and work.
What Does It Mean for AI to “Learn”?
AI learning is the computer’s ability to improve performance on a task using data rather than following explicit, hard-coded rules. Instead of instructing an AI system how to behave step by step, we expose it to examples—images, text, customer behavior, or sensor readings. The model then identifies patterns, correlations, and structures that allow it to generalize to new, unseen situations.
A streaming platform like Netflix recommends movies not because developers manually coded “If user likes X, suggest Y,” but because machine learning models observe millions of user interactions and detect patterns humans would never spot. Similarly, a logistics company like Amazon uses AI models to predict delivery times and optimize shipping routes through learned behaviors from historical data.
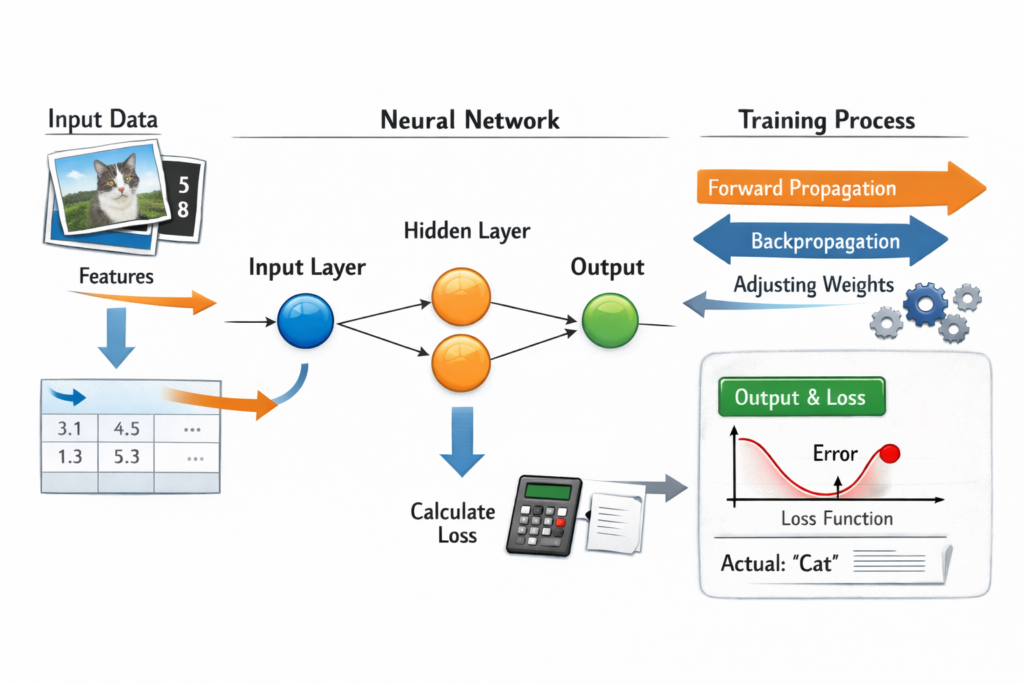
Core Components of An AI System
The Core Stages of How AI Systems Learn
1. Data Collection: Feeding the AI System
Every AI learning journey begins with data. This data can be collected from sensors, user interactions, databases, or online sources. The quality, volume, diversity, and cleanliness of data directly impact how well the model performs.
AI systems operate on the principle that “more data = better learning,” but this only holds when the data is relevant and representative. Biased, incomplete, or noisy data will produce flawed AI behavior. For example, a facial recognition system trained only on light-skinned faces will struggle to identify darker-skinned individuals—showing how critical balanced data is.
2. Data Preprocessing: Cleaning and Structuring
Raw data is rarely usable directly. Preprocessing involves cleaning missing values, removing noise, normalizing formats, and transforming features. This stage ensures the model focuses on meaningful patterns rather than irrelevant details.
For instance, customer data for a churn prediction project requires preparing features like customer age, tenure, total spend, and usage patterns. Preprocessing ensures all of these features are in comparable ranges and meaningful formats.
3. Algorithm Selection: Choosing the Brain of the System
Different algorithms excel in different situations:
- Decision Trees for structured decision-making
- Neural Networks for image, voice, or text
- Clustering algorithms such as K-Means (useful in your ongoing projects), for grouping customers or behaviors
- Sequential models like LSTMs and Transformers for time-series or language-based learning
Choosing an algorithm is not just technical—it’s strategic. A small dataset might perform poorly on deep learning models but excel using classical ML.
4. Training the Model: Learning From Examples
Training is when the model “sees” examples and adjusts its internal weights to reduce error. Every pass through the data helps refine its understanding. Training generally requires:
- Input data (X)
- Target labels (y) (for supervised learning)
- A loss function to quantify error
- An optimization algorithm like gradient descent
Imagine teaching a child to differentiate between cats and dogs by showing thousands of labeled images. The child gradually learns unique characteristics. Similarly, a neural network learns patterns from repeated exposure.
5. Evaluation: Measuring Accuracy and Errors
Once trained, models are tested on unseen data. Evaluation metrics vary depending on the task:
- Accuracy, precision, recall, and F1 score for classification
- MSE, RMSE, and MAE for regression
- Silhouette Score for clustering
- BLEU Score for language-based models
Evaluation tells us whether the model truly generalizes or simply memorizes the training data (overfitting).
6. Hyperparameter Tuning: The Fine Art of Optimization
Hyperparameters include learning rate, number of layers, cluster count, batch size, etc. Adjusting them can drastically change model performance.
For example, in clustering, selecting the correct number of clusters is crucial for meaningful grouping. In neural networks, tuning parameters ensures faster learning without instability.
7. Deployment: Taking AI Into the Real World
Once satisfied with performance, models are deployed into applications—web apps, mobile apps, backend systems, and embedded devices. Deployment ensures models respond in real-time, often utilizing infrastructure such as:
- Cloud-based GPU/TPU servers
- Containerization platforms like Docker
- Scalable API gateways
8. Continuous Learning: Improving Over Time
AI learning doesn’t stop at deployment. Real-world data drifts, user behaviors evolve, and models degrade. Continuous learning ensures systems stay relevant.
This includes:
- Retraining with new data
- Monitoring performance metrics
- Updating parameters
- Handling real-world edge cases
For example, recommendation engines continuously retrain on new user preferences.
AI Learning Workflow Comparison Table
| Stage | Purpose | Example Use Case | Tools/Algorithms Involved |
|---|---|---|---|
| Data Collection | Gather raw data | User activity for recommendations | Databases, APIs |
| Preprocessing | Clean and prepare | Customer churn dataset cleanup | Pandas, NumPy |
| Training | Learn from examples | Image classification | CNNs, Transformers |
| Evaluation | Assess performance | Validating churn predictions | Precision, Recall |
| Tuning | Improve accuracy | Determining best K in K-Means | Grid Search, Bayesian methods |
| Deployment | Real-world execution | Chatbot API | Docker, FastAPI |
| Continuous Learning | Ongoing improvement | Recommendation updates | Online learning |
Types of AI Learning Explained
Supervised Learning
This is the most common form of AI learning. The model learns from labeled examples.
Example: A fraud detection model learns from past transactions labeled “fraud” or “not fraud”.
Unsupervised Learning
The model finds natural patterns without labeled data.
Example: K-Means clustering on customer behavior to group users into segments based on spending or engagement.
Reinforcement Learning
The AI interacts with an environment and learns through reward and punishment.
Example: Game-playing models learning optimal strategies by trial and error.
How AI Improves Accuracy Over Time
AI systems improve via:
1. More Data
More examples → better pattern recognition.
Platforms like Amazon and Netflix rely heavily on data volume to sharpen predictions.
2. Better Data
Removing noise and improving feature quality has a profound impact.
3. Better Algorithms
Switching from classical ML to deep learning, or from LSTMs to Transformers, can significantly improve accuracy.
4. Hyperparameter Optimization
Fine-tuning learning rate, number of neurons, batch size, or cluster count ensures model stability.
5. Regular Retraining
Retraining on recent data keeps accuracy high amid changing trends.
6. Feedback Loops
User interactions provide real-time corrections—what users click, skip, or engage with helps the model improve.
Why Understanding AI Learning Matters
AI literacy is becoming as important as traditional computer literacy. Whether you’re applying for roles in data science or AI development (as you are preparing to), understanding the mechanics helps you:
- Interpret model behavior
- Build better AI systems
- Prepare for interviews
- Debug performance issues
- Explain AI to stakeholders
Conclusion
AI systems learn through a structured journey—from data to preprocessing, model training, evaluation, deployment, and continuous improvement. While algorithms form the brain, data acts as the fuel that shapes the intelligence. Understanding this entire pipeline is essential not just for building AI systems but for leveraging them effectively in business, research, or product development.