
Introduction: From Raw Data to Real-World Deployment
In a world increasingly driven by data, machine learning is no longer a niche skill reserved for researchers—it is a practical tool shaping industries, powering decisions, and transforming how organizations operate. Yet, many learners and even professionals struggle to understand how a machine learning project actually progresses from an idea to a deployed solution. This is where the machine learning workflow becomes essential. It is not just a sequence of steps but a structured approach that ensures reliability, scalability, and meaningful outcomes. In this comprehensive guide, you will explore the complete machine learning workflow—from data collection to deployment—explained in a way that is both practical and deeply informative.
What is a Machine Learning Workflow?
A machine learning workflow is a systematic process that guides the development of machine learning models. It includes all stages such as data collection, preprocessing, feature engineering, model training, evaluation, and deployment. Each stage plays a critical role in ensuring that the final model is accurate, efficient, and useful in real-world scenarios.
Unlike traditional programming, where rules are explicitly defined, machine learning relies on learning patterns from data. This makes the workflow more iterative and experimental. A small change in data preparation or model selection can significantly affect performance, which is why understanding each step is crucial.
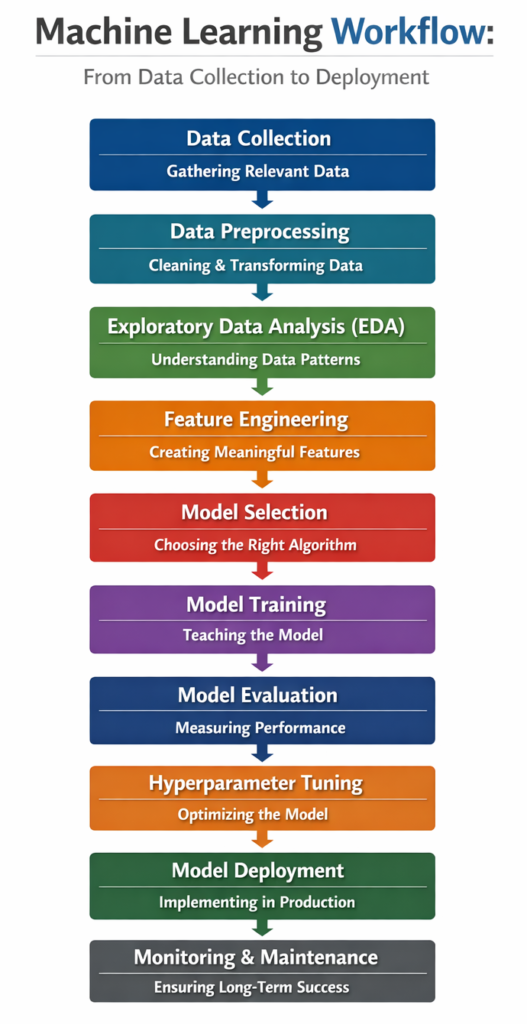
Step 1: Data Collection – The Foundation of Machine Learning
Every machine learning project begins with data, and the quality of your data directly determines the success of your model. Data can be collected from multiple sources such as databases, APIs, sensors, web scraping, surveys, or publicly available datasets.
The key challenge in this stage is not just gathering data but ensuring its relevance and diversity. For example, if you are building a recommendation system, your dataset must include user interactions, preferences, and behavioral patterns. Poor or biased data can lead to inaccurate predictions, making this step foundational and critical.
In real-world scenarios, data collection is often an ongoing process rather than a one-time task. Organizations continuously gather new data to improve model performance over time.
Step 2: Data Preprocessing – Cleaning and Preparing Data
Raw data is rarely usable in its original form. It often contains missing values, duplicates, noise, and inconsistencies. Data preprocessing involves cleaning and transforming this raw data into a structured format suitable for machine learning algorithms.
This step includes handling missing values, encoding categorical variables, normalizing numerical data, and removing outliers. For instance, if a dataset contains missing entries, you may choose to fill them using statistical methods like mean or median, or remove those records altogether.
Preprocessing ensures that the model learns meaningful patterns rather than noise. A well-prepared dataset significantly improves model accuracy and reduces training time.
Step 3: Exploratory Data Analysis (EDA) – Understanding the Data
Before building a model, it is essential to understand the data. Exploratory Data Analysis (EDA) helps uncover patterns, relationships, and trends within the dataset.
Through visualization techniques such as histograms, scatter plots, and correlation matrices, you can identify key insights. For example, EDA might reveal that certain features are highly correlated, which could influence feature selection later.
EDA is not just about visualization; it is about developing intuition. It allows you to ask the right questions and make informed decisions throughout the workflow.
Step 4: Feature Engineering – Creating Meaningful Inputs
Feature engineering is the process of transforming raw data into features that better represent the underlying problem. It is often considered one of the most important steps in the machine learning workflow.
This may involve creating new variables, combining existing ones, or selecting the most relevant features. For example, in a time-series dataset, you might extract features like day, month, or season from a timestamp.
Good feature engineering can significantly improve model performance, sometimes even more than choosing a complex algorithm. It requires both domain knowledge and creativity.
Step 5: Model Selection – Choosing the Right Algorithm
Once the data is prepared, the next step is selecting an appropriate machine learning model. The choice depends on the problem type—classification, regression, clustering, or recommendation.
Common algorithms include linear regression, decision trees, random forests, support vector machines, and neural networks. Each algorithm has its strengths and limitations. For instance, linear models are simple and interpretable, while deep learning models can capture complex patterns but require more data and computational power.
Selecting the right model involves experimentation and understanding the trade-offs between accuracy, interpretability, and computational cost.
Step 6: Model Training – Teaching the Model
In this stage, the selected model is trained using the prepared dataset. The model learns patterns by adjusting its internal parameters based on the input data.
The dataset is usually split into training and validation sets. The training set is used to teach the model, while the validation set helps evaluate its performance during training.
Training involves optimizing a loss function, which measures how far the model’s predictions are from actual values. The goal is to minimize this loss and improve accuracy.
Step 7: Model Evaluation – Measuring Performance
After training, the model must be evaluated to determine how well it performs on unseen data. This step ensures that the model generalizes well and is not overfitting.
Different metrics are used depending on the problem type:
- Classification: Accuracy, Precision, Recall, F1-score
- Regression: Mean Squared Error (MSE), Root Mean Squared Error (RMSE), R-squared
A robust evaluation process may also include cross-validation, which provides a more reliable estimate of model performance.
Step 8: Hyperparameter Tuning – Optimizing Performance
Hyperparameters are settings that control the behavior of a machine learning model. Unlike model parameters, they are not learned during training but must be set manually.
Techniques such as grid search, random search, and Bayesian optimization are used to find the best combination of hyperparameters. This step can significantly improve model performance but may require additional computational resources.
Hyperparameter tuning is often iterative and requires careful experimentation.
Step 9: Model Deployment – Bringing Models to Life
Once the model is optimized, it is deployed into a production environment where it can make real-world predictions. Deployment can take various forms, such as APIs, web applications, or embedded systems.
For example, a fraud detection model might be deployed within a banking system to analyze transactions in real time. Deployment involves integrating the model with existing systems and ensuring scalability and reliability.
This stage transforms a theoretical model into a practical solution.
Step 10: Monitoring and Maintenance – Ensuring Long-Term Success
Deployment is not the end of the workflow. Models must be continuously monitored to ensure they perform well over time. Changes in data patterns, known as data drift, can degrade model performance.
Monitoring involves tracking metrics, detecting anomalies, and updating the model when necessary. Maintenance may include retraining the model with new data or improving features.
This step ensures that the machine learning system remains effective and relevant.
Machine Learning Workflow Summary Table
| Step | Description | Key Activities | Importance |
|---|---|---|---|
| Data Collection | Gathering relevant data | APIs, databases, scraping | Foundation of model |
| Data Preprocessing | Cleaning and transforming data | Handling missing values, normalization | Improves data quality |
| EDA | Understanding data patterns | Visualization, correlations | Informs decisions |
| Feature Engineering | Creating useful features | Feature selection, transformation | Boosts performance |
| Model Selection | Choosing algorithm | Comparing models | Affects accuracy |
| Training | Teaching the model | Parameter optimization | Core learning phase |
| Evaluation | Measuring performance | Metrics, validation | Ensures reliability |
| Hyperparameter Tuning | Optimizing model | Grid search, tuning | Enhances accuracy |
| Deployment | Using model in real-world | APIs, apps | Practical application |
| Monitoring | Maintaining model | Updates, retraining | Long-term success |
Common Challenges in Machine Learning Workflow
Despite its structured nature, the machine learning workflow comes with several challenges. Data quality issues, lack of domain knowledge, and overfitting are among the most common problems. Additionally, deployment and scalability can be complex, especially in large-scale systems.
Another major challenge is reproducibility. Ensuring that results can be replicated requires proper documentation and version control. Addressing these challenges requires both technical expertise and strategic thinking.
Best Practices for an Effective ML Workflow
To build a successful machine learning pipeline, it is important to follow best practices. These include maintaining clean and well-documented code, using version control for data and models, and automating repetitive tasks.
Collaboration between data scientists, engineers, and domain experts also plays a crucial role. A well-coordinated team can significantly improve the efficiency and effectiveness of the workflow.
Conclusion
The machine learning workflow is a comprehensive process that transforms raw data into actionable insights and real-world applications. Each step, from data collection to monitoring, plays a vital role in ensuring the success of a machine learning project.
Understanding this workflow not only helps in building better models but also prepares you to tackle real-world challenges. Whether you are a student, a data scientist, or a professional, mastering this process is essential for leveraging the true potential of machine learning.