
Introduction
Imagine typing a single sentence—“a futuristic city floating above the ocean at sunset”—and watching a breathtaking, ultra-realistic image materialize out of thin air. No camera. No paintbrush. No 3D rendering studio. Just words and algorithms. The realism of modern AI-generated images feels almost magical, yet behind that magic lies one of the most fascinating breakthroughs in machine learning: diffusion models.
In this article, we’ll uncover how diffusion models work step-by-step, why they produce such stunningly realistic results, and how they power today’s most advanced AI art generators. If you’ve ever wondered why AI art looks so real—and sometimes indistinguishable from photography—this deep dive will reveal the science behind the illusion.
What Are Diffusion Models in AI?
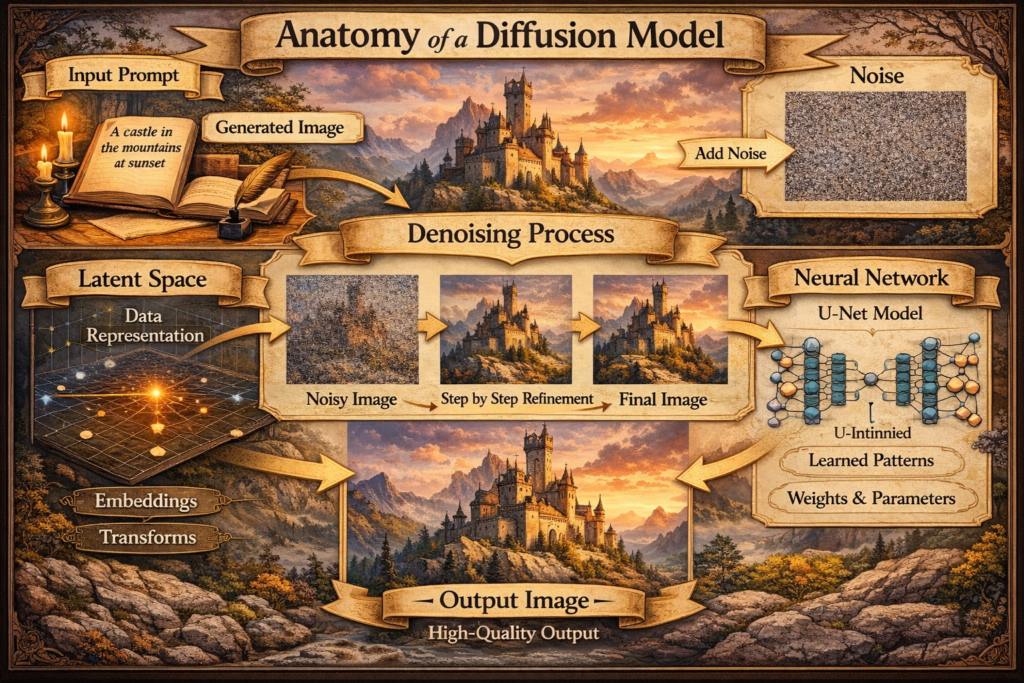
Diffusion models are a class of generative AI systems designed to create data—especially images—by learning how to reverse a gradual noise process. In simple terms, they learn how to turn static noise into meaningful pictures.
Unlike older generative models such as GANs (Generative Adversarial Networks), diffusion models generate images progressively. They begin with pure random noise and slowly refine it over many steps, removing noise bit by bit until a coherent image emerges. This method gives them exceptional control over detail, structure, and realism.
Many cutting-edge tools like Leonardo AI, Runway ML, and Playground AI rely on diffusion-based architectures to create photorealistic outputs from text prompts.
The Core Idea: Learning to Reverse Noise
At the heart of diffusion models lies a beautifully simple yet powerful idea: if you can learn how to destroy an image gradually, you can learn how to rebuild it.
The training process happens in two major phases:
1. The Forward Process (Adding Noise)
During training, a clean image is gradually corrupted with random noise over hundreds or thousands of small steps. Each step makes the image slightly more distorted. Eventually, after enough steps, the image becomes pure noise—completely unrecognizable.
This process is mathematically controlled, so the model knows exactly how much noise is added at each step. Think of it like slowly blurring and scrambling a photo until nothing remains but static.
The key insight? This process is predictable.
2. The Reverse Process (Removing Noise)
Now comes the magic.
The model is trained to reverse this corruption step-by-step. At each stage, it learns how to remove a tiny amount of noise and recover a slightly cleaner version of the image. Over time, it becomes incredibly good at reconstructing images from noisy inputs.
After training on millions of images, the model understands patterns such as:
- How faces are structured
- How lighting behaves
- How textures look in different materials
- How perspective and depth work
By learning to denoise effectively, the model learns how images are constructed in the real world.
Step-by-Step: How Diffusion Models Generate an Image
Let’s break down what happens when you type a prompt into an AI image generator.
Step 1: Start with Random Noise
The system begins with a canvas filled with random noise—similar to television static. There is no structure, no objects, no recognizable shapes.
This is intentional. The model’s job is to transform chaos into meaning.
Step 2: Encode the Text Prompt
Your text prompt—such as “a cinematic portrait of a cyberpunk warrior”—is converted into numerical representations by a language model. These embeddings guide the image creation process.
The model now has a mathematical understanding of:
- What “cyberpunk” visually implies
- What a “warrior” might look like
- What “cinematic portrait” lighting involves
The prompt becomes a conditioning signal.
Step 3: Iterative Denoising
The diffusion model begins by gradually removing noise. At each step, it predicts what the image should look like with slightly less noise, guided by the text embeddings.
Over dozens or hundreds of iterations:
- Shapes begin to form
- Colors stabilize
- Details sharpen
- Lighting becomes coherent
Instead of generating everything at once, the model sculpts the image layer by layer.
Step 4: Refinement and Detail Enhancement
As noise decreases, the model focuses on high-frequency details—like skin texture, reflections, fabric folds, and shadows. This is where realism emerges.
Because the process is gradual, diffusion models avoid many of the distortions and artifacts that older models struggled with.
The final result is a highly detailed, context-aware image aligned with your prompt.
Why Diffusion Models Produce Such Realistic Images
Diffusion models excel because of several powerful characteristics:
1. Gradual Generation Improves Stability
Unlike GANs, which generate images in one pass, diffusion models refine progressively. This reduces instability and improves visual coherence.
2. Strong Understanding of Visual Patterns
Since they train on massive datasets, diffusion models learn statistical relationships in real-world imagery—how light interacts with surfaces, how anatomy is structured, and how environments are composed.
This deep statistical knowledge allows them to recreate realism convincingly.
3. Fine-Grained Control
Diffusion models can be conditioned on:
- Text prompts
- Image references
- Style guidance
- Masks (for inpainting)
Tools like ArtSmart AI allow users to control style, lighting, and even camera angles because diffusion models respond smoothly to guidance signals.
4. High Resolution Capability
Modern architectures use latent diffusion, where the denoising process happens in a compressed space. This dramatically reduces computational cost while enabling high-resolution output.
That’s why platforms like Creative Fabrica’s CF Spark can generate sharp, print-ready visuals.
The Role of Latent Space: Where the Real Magic Happens
Most modern diffusion systems use something called latent diffusion models (LDMs).
Instead of operating directly on full-resolution images, they:
- Compress the image into a smaller latent representation
- Perform the diffusion process in this compressed space
- Decode the final latent back into a high-resolution image
This approach makes generation faster and more scalable while preserving intricate details.
It’s like sculpting a statue using a blueprint before revealing the full-sized masterpiece.
How Diffusion Models Understand Lighting and Texture
One reason AI art looks so real is that diffusion models implicitly learn physics-like behaviors from data.
They don’t understand physics conceptually—but statistically, they learn:
- Shadows fall opposite light sources
- Skin reflects light softly
- Metal surfaces have sharp highlights
- Depth affects focus and blur
By observing millions of examples, the model internalizes these correlations. When generating images, it reproduces them naturally.
This is why AI portraits often feature realistic skin pores, reflections in eyes, and accurate environmental lighting.
Training Diffusion Models: Why They’re So Powerful
Training these models requires:
- Massive datasets
- High-performance GPUs
- Billions of parameters
During training, the model learns to predict noise added at each step. Over time, it becomes extremely good at estimating the “clean” image hidden beneath the noise.
Because the objective is well-defined (predict the noise accurately), training is more stable compared to adversarial methods like GANs.
This stability contributes directly to realism.
From Noise to Art: The Psychological Impact
Diffusion models don’t just produce sharp images—they produce emotionally convincing ones. When lighting, color harmony, and composition align naturally, the human brain interprets the image as authentic.
Realism isn’t only about pixel detail—it’s about coherence.
When an AI-generated face has correct symmetry, natural lighting gradients, and believable texture, our visual system accepts it as real.
That’s the true magic of diffusion models.
The Future of Diffusion Models in AI Art
Diffusion models are evolving rapidly. Researchers are working on:
- Faster sampling methods
- Better text-image alignment
- Video diffusion models
- 3D object generation
- Real-time rendering
The same core idea—reversing noise—continues to power breakthroughs across creative industries.
From filmmaking and gaming to marketing and product design, diffusion-based systems are reshaping digital creativity.
Conclusion: The Science Behind the Illusion
AI art looks so real because diffusion models mimic the structure of reality through gradual refinement. By learning to reverse noise step-by-step, these models reconstruct images with astonishing accuracy.
They don’t “see” or “imagine” the way humans do—but they statistically understand how the world looks. Through millions of examples and thousands of denoising steps, chaos transforms into clarity.
What feels like magic is actually mathematics, probability, and deep neural networks working in harmony.
And the more these models evolve, the thinner the line between artificial and authentic will become.
Also Read: AI-Powered Creativity: How Machines Generate Art That Inspires