
Introduction: How Machines Learn from Data
In a world increasingly driven by data, the ability of machines to “learn” from examples is no longer a futuristic concept—it is a practical reality shaping industries, careers, and everyday decisions. From personalized Netflix recommendations to fraud detection in banking, supervised learning sits at the core of modern artificial intelligence. But what exactly is supervised learning, and why is it so powerful? This guide takes you beyond surface-level definitions and dives into how it works, the algorithms behind it, and why mastering it is essential for students, data professionals, and tech enthusiasts alike.
What is Supervised Learning?
Supervised learning is a type of machine learning where a model is trained using labeled data. In simple terms, the algorithm learns from a dataset that already contains the correct answers. Each input data point is paired with an output label, and the model’s goal is to learn a mapping between inputs and outputs.
For example, imagine teaching a child to identify fruits. You show them images of apples, bananas, and oranges, each labeled correctly. Over time, the child learns to recognize patterns and can identify new fruits. Similarly, supervised learning algorithms analyze labeled datasets to predict outcomes for unseen data.
This approach is called “supervised” because the learning process is guided by known outcomes. The algorithm continuously adjusts itself to minimize the difference between its predictions and the actual results, improving accuracy over time.
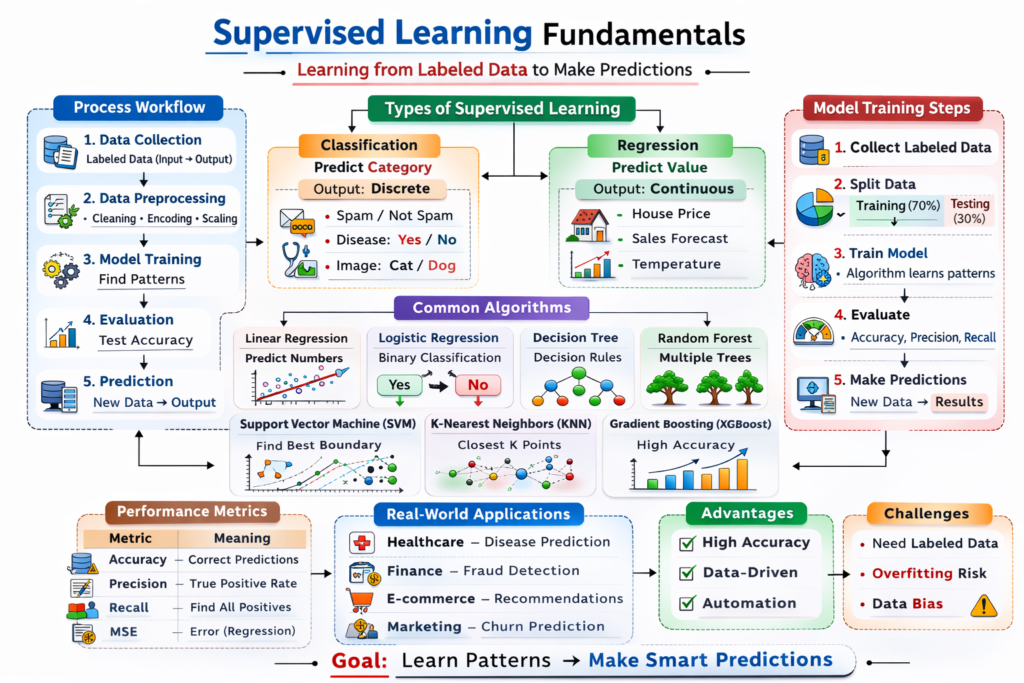
How Supervised Learning Works
Supervised learning follows a structured process that transforms raw data into predictive insights. While the concept may seem simple, the underlying mechanics involve mathematical optimization, statistical modeling, and iterative learning.
1. Data Collection and Labeling
The first step involves gathering a dataset that includes both input features and corresponding output labels. The quality of this data is crucial because the model learns directly from it. Poor or biased data leads to poor predictions.
2. Data Preprocessing
Raw data is rarely ready for modeling. It must be cleaned, normalized, and transformed. This includes handling missing values, encoding categorical variables, and scaling numerical features to ensure consistent performance across algorithms.
3. Model Selection
Different problems require different algorithms. For example, predicting house prices may require regression models, while classifying emails as spam or not spam requires classification algorithms.
4. Training the Model
During training, the algorithm processes the data and adjusts its internal parameters to minimize error. This is typically done using optimization techniques such as gradient descent.
5. Evaluation
After training, the model is tested on unseen data to evaluate its performance. Metrics such as accuracy, precision, recall, and mean squared error help determine how well the model generalizes.
6. Prediction and Deployment
Once validated, the model can be used in real-world applications to make predictions on new data.
Types of Supervised Learning
Supervised learning can broadly be divided into two categories, each serving distinct purposes.
1. Classification
Classification involves predicting categorical outcomes. The output variable is discrete, meaning it belongs to a specific class or category.
Examples include:
- Email spam detection (spam or not spam)
- Disease diagnosis (positive or negative)
- Image recognition (cat, dog, or other)
2. Regression
Regression involves predicting continuous numerical values. The output variable is a real number.
Examples include:
- Predicting house prices
- Forecasting sales revenue
- Estimating temperature
Common Supervised Learning Algorithms
A wide variety of algorithms fall under supervised learning, each with its own strengths, weaknesses, and use cases.
1. Linear Regression
Linear regression is one of the simplest algorithms used for predicting continuous values. It assumes a linear relationship between input variables and the output. Despite its simplicity, it is widely used in finance, economics, and business analytics.
2. Logistic Regression
Despite its name, logistic regression is used for classification tasks. It predicts the probability of a categorical outcome using a logistic function, making it ideal for binary classification problems.
3. Decision Trees
Decision trees use a tree-like structure to make decisions based on feature values. They are easy to interpret and visualize but can overfit if not properly controlled.
4. Random Forest
Random forest is an ensemble method that combines multiple decision trees to improve accuracy and reduce overfitting. It is robust and widely used in real-world applications.
5. Support Vector Machines (SVM)
SVM finds the optimal boundary (hyperplane) that separates data into classes. It is effective in high-dimensional spaces and is commonly used in text classification and image recognition.
6. K-Nearest Neighbors (KNN)
KNN is a simple algorithm that classifies data based on the closest neighbors. It is intuitive but can be computationally expensive for large datasets.
7. Gradient Boosting Algorithms
Algorithms like Gradient Boosting, XGBoost, and LightGBM build models sequentially, correcting errors from previous models. They are highly powerful and dominate many machine learning competitions.
Comparison of Common Supervised Learning Algorithms
| Algorithm | Type | Strengths | Weaknesses | Use Cases |
|---|---|---|---|---|
| Linear Regression | Regression | Simple, fast, interpretable | Limited to linear relationships | Price prediction, forecasting |
| Logistic Regression | Classification | Probabilistic output, easy to implement | Not suitable for complex relationships | Binary classification |
| Decision Trees | Both | Easy to interpret, no data scaling needed | Prone to overfitting | Rule-based decision systems |
| Random Forest | Both | High accuracy, reduces overfitting | Less interpretable | Fraud detection, recommendation |
| SVM | Both | Works well in high dimensions | Computationally intensive | Text classification, image tasks |
| KNN | Both | Simple, no training phase | Slow with large data | Pattern recognition |
| Gradient Boosting | Both | Very high performance | Complex, requires tuning | Competitive ML tasks |
Key Concepts in Supervised Learning
Understanding supervised learning requires familiarity with several core concepts that influence model performance.
1. Overfitting and Underfitting
Overfitting occurs when a model learns noise in the data instead of the underlying pattern, leading to poor generalization. Underfitting happens when the model is too simple to capture the data’s complexity.
2. Bias-Variance Tradeoff
Bias refers to errors due to overly simplistic models, while variance refers to sensitivity to fluctuations in training data. A good model balances both.
3. Training vs Testing Data
Data is split into training and testing sets to evaluate performance. This ensures the model performs well on unseen data.
4. Cross-Validation
Cross-validation improves reliability by dividing data into multiple subsets and testing the model multiple times.
Advantages of Supervised Learning
Supervised learning offers several benefits that make it widely adopted across industries.
- High Accuracy: When trained on quality data, models can achieve impressive predictive performance.
- Clear Objective: The presence of labeled data provides a clear goal for learning.
- Wide Applicability: Used in healthcare, finance, marketing, and more.
- Ease of Evaluation: Performance metrics are well-defined and easy to interpret.
Limitations of Supervised Learning
Despite its strengths, supervised learning also has challenges.
- Data Dependency: Requires large amounts of labeled data, which can be expensive and time-consuming to obtain.
- Limited Generalization: Models may struggle with unseen scenarios outside the training data.
- Risk of Bias: Biased data leads to biased predictions.
- Overfitting Issues: Complex models may memorize rather than learn patterns.
Real-World Applications of Supervised Learning
Supervised learning is deeply embedded in modern technology and business operations.
- Healthcare: Disease prediction, medical image analysis
- Finance: Credit scoring, fraud detection
- E-commerce: Recommendation systems, customer segmentation
- Marketing: Customer churn prediction
- Autonomous Systems: Object detection and navigation
These applications demonstrate how supervised learning transforms raw data into actionable insights, enabling smarter decisions.
Best Practices for Implementing Supervised Learning
To achieve optimal results, practitioners must follow structured approaches.
- Focus on data quality over quantity
- Perform feature engineering to improve model input
- Use appropriate evaluation metrics based on the problem
- Regularly validate and tune models
- Monitor performance after deployment
These practices ensure models remain accurate and reliable over time.
Future of Supervised Learning
As data continues to grow, supervised learning will evolve with advancements in deep learning, automation, and hybrid models. While the other types of machine learning (unsupervised, semi-supervised and reinforcement learning) are gaining traction, supervised learning remains foundational due to its reliability and interpretability.
The future will likely see more widespread adoption of automated machine learning (AutoML), reducing barriers to entry and enabling more professionals to leverage these techniques effectively.