
Introduction
(A Deep Dive Into the Mechanics Behind Modern AI Reasoning)
Large Language Models (LLMs) have exploded into the mainstream so quickly that most people see only the magic, not the machinery. We type a question, hit enter, and—like a digital oracle—the model replies with something structured, intelligent, and often shockingly insightful. But behind this seamless interaction lies a world of mathematics, neural computation, and emergent reasoning that most users never glimpse.
The truth is far more fascinating than the myth: LLMs do not “think” like humans, yet they produce reasoning that often feels human because of how deeply they understand patterns in language. In this article, we uncover the hidden architecture, training process, and emergent reasoning abilities that make LLMs the most powerful technology of the modern era.
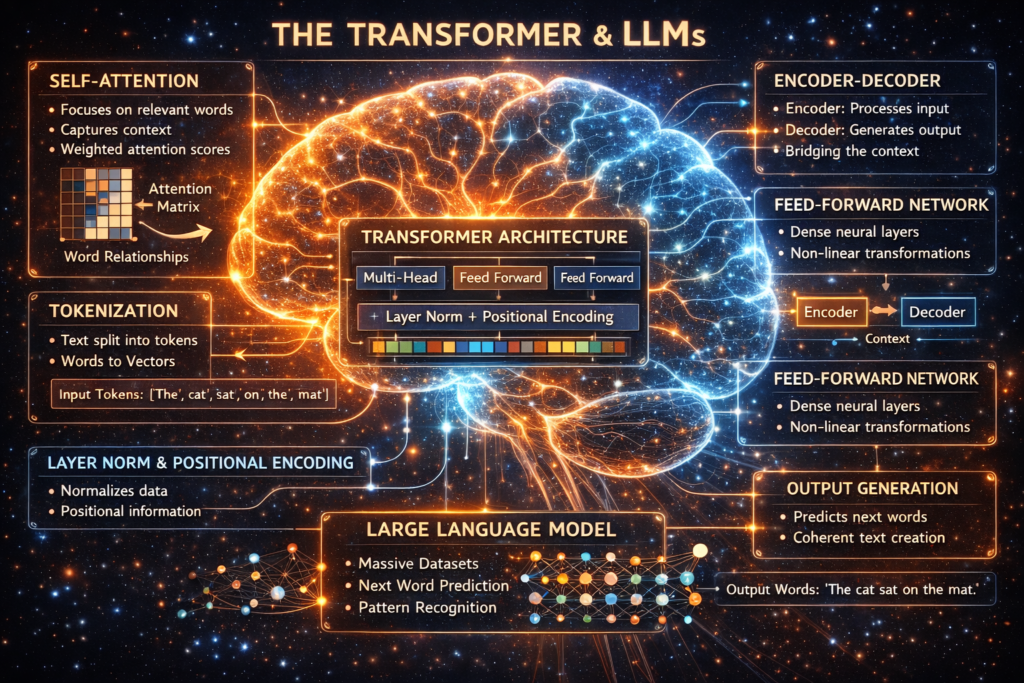
What Exactly Is a Large Language Model?
A Large Language Model is a type of neural network trained to predict the next word or token in a sequence. While this may sound simple, prediction at scale—trained on trillions of tokens—produces capabilities that go far beyond autocomplete. The sophisticated architectures behind these models analyze relationships between words, phrases, sentences, and concepts in ways that approximate reasoning.
Unlike traditional software, where logic is programmed explicitly, LLMs learn patterns implicitly. They form high-dimensional internal representations that encode meaning, context, style, and even intent. This allows an LLM to generate coherent essays, write code, summarize complex documents, or even explain its reasoning steps. Modern architectures such as the Transformer made this scale possible, enabling models to analyze context in parallel and uncover linguistic patterns too complex for classical machine learning systems.
How Transformers Revolutionized Understanding
The breakthrough that unlocked LLMs is the Transformer architecture, which introduced a process called self-attention. Unlike older recurrent networks that read text sequentially, Transformers process all tokens simultaneously and determine which pieces of information matter most. This allows models to capture long-range dependencies—such as linking early context to later meaning—and generate accurate outputs without losing track of earlier details.
Transformers also support scalability: by stacking hundreds of layers and billions of parameters, they develop increasingly nuanced internal structures capable of abstract reasoning. This architecture became the foundation of modern AI systems. Tools and frameworks like TensorFlow and Hugging Face, widely used in AI development, empower researchers and engineers to build, fine-tune, and deploy transformer-based models across industries.
How LLMs Learn: Training, Tokens, and Representation
At their core, LLMs learn through exposure to enormous amounts of text. During training, models break data into “tokens”—tiny units representing words, subwords, or characters—and repeatedly predict the next token in a sequence. Each prediction updates internal weights, gradually shaping a model that understands grammar, facts, semantics, style, and reasoning patterns. What makes this process powerful is the emergent structure within the model.
Without being explicitly taught about “topics,” “emotion,” “intent,” or “logic,” LLMs begin to self-organize these concepts as geometric structures inside the network’s vector space. These internal representations function like a massive, multidimensional map of meaning, enabling the model to infer relationships, analogies, and even causal patterns.
For those interested in training, optimization, and system design, advanced tools like Weights & Biases (https://wandb.ai/) offer experiment tracking and model visualization that illuminate this hidden learning process.
The Truth About “Reasoning” in LLMs
One of the most misunderstood aspects of LLMs is their ability to reason. LLMs do not reason like humans; instead, they reproduce reasoning-like behavior by learning the statistical structure of logical explanations, step-by-step solutions, and problem-solving strategies.
Over billions of training samples, the model internalizes how humans express reasoning. When prompted, it generates solutions that appear logically structured—not because it “understands” in a conscious sense, but because it has built an internal model of how correct reasoning should look and behave. Surprisingly, this approximation is often powerful enough to solve mathematical problems, write algorithms, and provide strategic advice.
Recent research has introduced techniques like chain-of-thought prompting, which encourages models to produce explicit reasoning steps, improving accuracy on tasks like analysis, planning, and multi-step problem solving.
Why LLMs Seem to “Understand” Context
Context is where LLMs shine. Through self-attention, models evaluate the relevance of each token relative to every other token, allowing them to produce fine-grained contextual awareness. Unlike humans—who use intuition and lived experience—LLMs use vector math to calculate semantic distance and contextual relevance.
The richer the prompt, the more the model can anchor its internal computations to meaningful patterns. This is why well-crafted prompts yield superior results. The model is not just reading text; it’s mapping the text into a dynamic web of relationships within its internal state. The more coherent your prompt, the more coherent the output.
Emergent Abilities: The Hidden Layer of Intelligence
At larger scales, LLMs begin exhibiting behaviors that were never explicitly programmed:
- solving logic puzzles
- translating with near-native fluency
- producing structured code
- analyzing emotions in text
- predicting missing information
- generating accurate explanations for complex topics
These are known as emergent abilities. They appear only when models reach a certain size and complexity because the network becomes dense enough to encode higher-level abstractions. As models grow, they transition from memorizing patterns to synthesizing new information in meaningful ways. This is why large models outperform smaller ones: they simply have more representational capacity to internalize sophisticated structures.
The Role of Reinforcement Learning and Human Feedback
Emergent abilities alone aren’t enough to make LLMs helpful or aligned with human expectations. This is where Reinforcement Learning from Human Feedback (RLHF) enters. After pretraining, models undergo a second phase where human evaluators guide them toward helpful, safe, and context-aware responses.
This process refines the model’s behavior, making responses more conversational, accurate, and aligned with user intent. RLHF also reduces undesirable outputs like hallucinations, biased statements, or unsafe content. Through thousands of preference comparisons, the model learns which kinds of answers are preferred by humans and adjusts accordingly. Over time, this produces smoother reasoning, clearer explanations, and more consistent logic.
Why LLMs Sometimes Get Things Wrong
Despite their impressive capabilities, LLMs are not perfect. Their knowledge is limited to the data they were trained on, and they lack real-world grounding. They may produce:
- hallucinations (confident but incorrect answers)
- outdated information
- misinterpretations of ambiguous queries
- overly generic or vague explanations
These errors arise because the model is predicting patterns, not retrieving facts from a database. When information is missing or unclear, the model relies on statistical generalization, which can produce inaccuracies. Understanding this limitation helps users prompt more effectively and evaluate outputs critically.
How LLMs Are Making Industries Smarter
Today, LLMs are integrated into business, education, research, healthcare, and creative industries because of their versatility. They can summarize reports, analyze trends, write emails, assist coders, support customer service, and even automate workflows. Beyond content generation, LLMs power AI agents, autonomous systems that can browse the web, execute tasks, or integrate with automation platforms.
Businesses now increasingly rely on LLM-driven tools like Zapier to automate processes or integrate AI into operational systems without writing code. The future will bring even smarter interactions: personalized reasoning engines, context-aware agents, multimodal analysis, and deeply integrated enterprise intelligence systems.
The Future of LLM Reasoning: Toward True Cognitive Agents
We are moving toward AI systems that blend reasoning, memory, planning, and tool usage into unified intelligent agents. These systems will not just generate text—they will execute tasks, verify outputs, search for missing information, and refine their answers. Combined with multimodal models capable of vision, audio, and sensor analysis, the boundaries between digital reasoning and human-like cognition will continue to blur.
However, as LLMs grow stronger, ethical considerations—fairness, transparency, bias reduction, and responsible deployment—must guide their evolution.
Also Read: How Artificial Intelligence Actually Works -Explained Simply