
Introduction: When Data Speaks Without Instructions
What if machines could uncover meaningful insights without being explicitly told what to look for? In a world overflowing with raw, unlabeled data—customer behavior, images, transactions, and sensor signals—this is not just a theoretical idea but a practical necessity. Unsupervised learning stands at the center of this capability, enabling systems to identify hidden structures, relationships, and patterns without predefined answers. Unlike supervised learning, where models are trained on labeled datasets, unsupervised learning works in the dark—yet often reveals the most valuable insights.
From segmenting customers into meaningful groups to compressing massive datasets into manageable forms, unsupervised learning powers many modern data science applications. This article explores the fundamentals of unsupervised learning, focusing on clustering, dimensionality reduction, and real-world use cases, helping students and professionals build a strong conceptual foundation.
What is Unsupervised Learning?
Unsupervised learning is a type of machine learning where algorithms analyze and interpret datasets without labeled outputs. Instead of predicting outcomes, the model attempts to understand the structure of the data by identifying patterns, similarities, and relationships among data points.
This approach is especially useful when labeled data is scarce, expensive, or unavailable. For example, in customer analytics, businesses may not know predefined categories but still want to group customers based on behavior. Unsupervised learning helps discover these natural groupings.
Key Characteristics of Unsupervised Learning
- No labeled data or target variable
- Focus on pattern discovery and structure detection
- Used for exploratory data analysis
- Often serves as a preprocessing step for supervised learning
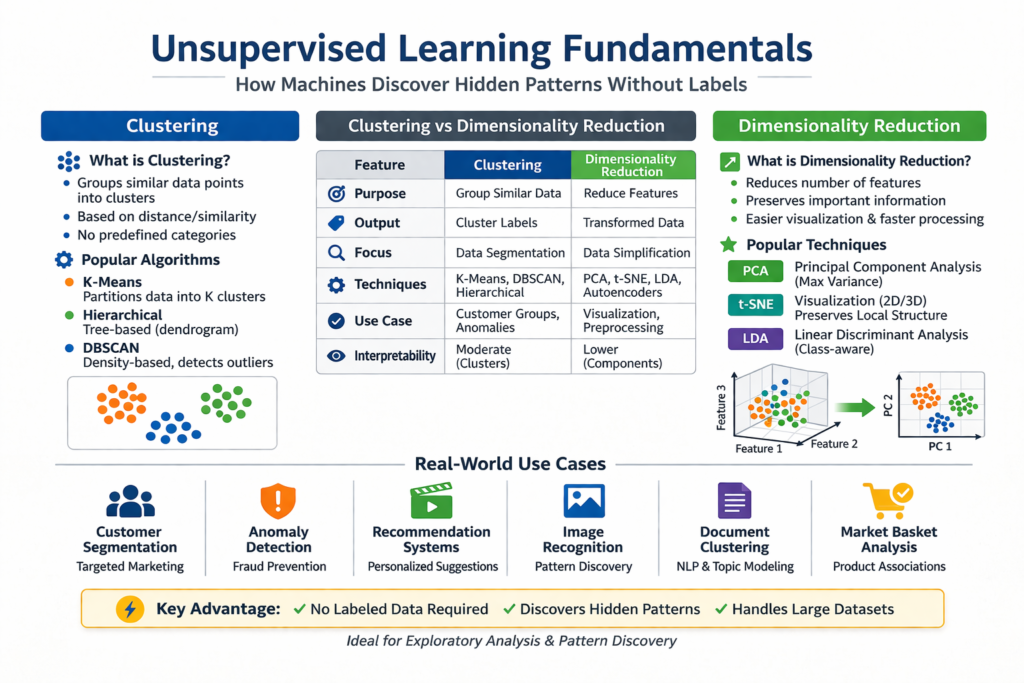
Clustering: Grouping Data Based on Similarity
What is Clustering?
Clustering is one of the most widely used unsupervised learning techniques. It involves grouping similar data points together into clusters, such that items within the same cluster are more similar to each other than to those in other clusters.
This method is particularly useful in scenarios where categories are not predefined, and we want to uncover natural groupings within data.
How Clustering Works
Clustering algorithms measure similarity using distance metrics such as Euclidean distance, Manhattan distance, or cosine similarity. Based on these measures, the algorithm assigns data points into clusters.
Different algorithms follow different approaches:
- Some define a fixed number of clusters (e.g., K-Means)
- Others identify clusters based on density (e.g., DBSCAN)
- Some build hierarchical structures (e.g., Agglomerative Clustering)
Popular Clustering Algorithms
1. K-Means Clustering
K-Means partitions data into K clusters by minimizing the distance between data points and cluster centroids. It is simple, efficient, and widely used, but requires specifying the number of clusters in advance.
2. Hierarchical Clustering
This method builds a tree-like structure of clusters, either by merging smaller clusters (agglomerative) or splitting larger ones (divisive). It provides a visual representation called a dendrogram.
3. DBSCAN (Density-Based Spatial Clustering)
DBSCAN groups data based on density, making it effective for identifying clusters of arbitrary shapes and detecting noise or outliers.
Dimensionality Reduction: Simplifying Complex Data
What is Dimensionality Reduction?
Dimensionality reduction is the process of reducing the number of features (variables) in a dataset while preserving as much information as possible. High-dimensional data can be difficult to visualize, process, and interpret, often leading to issues like overfitting and increased computational cost.
This technique transforms data into a lower-dimensional space, making it more manageable and meaningful.
Why Dimensionality Reduction Matters
- Improves model performance by removing noise
- Reduces computational complexity
- Helps visualize high-dimensional data
- Mitigates the curse of dimensionality
Popular Dimensionality Reduction Techniques
1. Principal Component Analysis (PCA)
PCA transforms data into a set of orthogonal components that capture maximum variance. It is widely used for feature reduction and visualization.
2. t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE is primarily used for visualization, especially in 2D or 3D spaces. It preserves local relationships and is effective for identifying clusters visually.
3. Linear Discriminant Analysis (LDA)
Although often used in supervised settings, LDA can also be applied for dimensionality reduction when class structure is partially known.
Clustering vs Dimensionality Reduction: Key Differences
| Feature | Clustering | Dimensionality Reduction |
|---|---|---|
| Purpose | Group similar data points | Reduce number of features |
| Output | Cluster labels | Transformed feature space |
| Focus | Data segmentation | Data simplification |
| Techniques | K-Means, DBSCAN, Hierarchical | PCA, t-SNE, LDA |
| Use Case | Customer segmentation, anomaly detection | Visualization, preprocessing |
| Interpretability | Moderate | Often lower but insightful |
While both techniques are unsupervised, they serve different purposes. Clustering focuses on grouping data, whereas dimensionality reduction simplifies the data representation.
Real-World Use Cases of Unsupervised Learning
1. Customer Segmentation
Businesses use clustering algorithms to group customers based on purchasing behavior, preferences, and demographics. This allows companies to tailor marketing strategies, improve customer experience, and increase revenue.
For example, an e-commerce platform can identify high-value customers, occasional buyers, and discount seekers, enabling personalized campaigns.
2. Anomaly Detection
Unsupervised learning helps detect unusual patterns or outliers in data. This is widely used in fraud detection, network security, and system monitoring.
For instance, in banking, transactions that deviate significantly from normal behavior can be flagged as potential fraud.
3. Recommendation Systems
Although often combined with supervised methods, unsupervised learning plays a role in identifying similarities between users or items. This helps recommend products, movies, or content based on user behavior.
4. Image and Pattern Recognition
Dimensionality reduction techniques help process high-dimensional image data efficiently. Clustering can group similar images, enabling applications like facial recognition and image categorization.
5. Document Clustering and Topic Modeling
Unsupervised learning is widely used in natural language processing (NLP) to group similar documents or extract topics from large text corpora. This is useful in search engines, content organization, and sentiment analysis.
6. Market Basket Analysis
Retailers use unsupervised learning to identify associations between products. For example, if customers frequently buy bread and butter together, stores can optimize product placement and promotions.
Advantages of Unsupervised Learning
1. No Need for Labeled Data (Cost & Time Efficient)
Unsupervised learning does not require pre-labeled datasets, which are often expensive and time-consuming to create. This makes it highly practical in real-world scenarios where data is abundant but labels are unavailable.
2. Discovers Hidden Patterns
These algorithms can uncover structures, relationships, and trends that are not immediately visible. For example, clustering can reveal customer segments that businesses didn’t explicitly define.
3. Scalable to Large Datasets
Unsupervised methods can handle vast amounts of data efficiently, making them suitable for big data applications such as social media analysis, recommendation systems, and IoT data processing.
4. Useful for Exploratory Data Analysis (EDA)
It is often used as a first step in understanding datasets. By identifying patterns and structures, it helps data scientists form hypotheses and guide further analysis.
Challenges and Limitations
1. No Ground Truth (Hard to Evaluate)
Since there are no labeled outputs, it becomes difficult to measure how accurate or correct the results are. Evaluation often relies on indirect metrics or domain knowledge.
2. Results Can Be Subjective
Different algorithms or parameter choices can produce different results, and there is often no single “correct” answer. Interpretation depends heavily on context.
3. Sensitive to Noise and Outliers
Unsupervised models can be easily affected by irrelevant or extreme data points, which may distort patterns or lead to misleading clusters.
4. Algorithm & Parameter Selection is Complex
Choosing the right algorithm (e.g., K-Means vs DBSCAN) and tuning parameters (like number of clusters) requires experience, experimentation, and domain understanding.
When Should You Use Unsupervised Learning?
1. When You Have Unlabeled Data
If your dataset lacks labels or predefined outcomes, unsupervised learning is the ideal approach to extract insights.
2. For Pattern Discovery
Use it when your goal is to explore relationships, groupings, or structures within data rather than predict outcomes.
3. For Feature Engineering & Preprocessing
Dimensionality reduction techniques (like PCA) help simplify data, remove noise, and improve the performance of supervised models.
4. When Working with High-Dimensional Data
In datasets with many features (e.g., images, text), unsupervised learning helps reduce complexity and make analysis more manageable.
Note: Unsupervised learning is best used as an exploration and discovery tool, especially in early stages of data analysis, where understanding the data is more important than making predictions.
Conclusion: Unlocking the Hidden Value of Data
Unsupervised learning is a powerful approach that enables machines to uncover insights without explicit guidance. By leveraging techniques like clustering and dimensionality reduction, machines can transform raw, unstructured data into meaningful information.
Whether it’s segmenting customers, detecting anomalies, or simplifying complex datasets, unsupervised learning plays a critical role in modern data science. As the volume of data continues to grow, mastering these techniques is not just beneficial—it is essential.