
Introduction: Why Are GRUs Quietly Replacing LSTMs in Modern AI?
In the rapidly evolving world of deep learning, efficiency often determines success. While Long Short-Term Memory (LSTM) networks once dominated sequence modeling tasks such as language translation, speech recognition, and time-series forecasting, a newer architecture—GRU Networks -Gated Recurrent Units—has been steadily gaining ground. GRUs promise similar performance with fewer parameters, faster training, and simpler implementation. But what exactly makes GRUs so effective, and how do they differ from LSTMs?
If you’re a student, data scientist, or AI enthusiast trying to understand modern neural network architectures, this article breaks down GRUs in a clear, structured, and practical way. By the end, you’ll not only understand how GRUs work but also when and why to use them over LSTMs.
What Are Recurrent Neural Networks (RNNs)? A Quick Refresher
Before diving into GRUs, it’s important to understand the problem they solve. Traditional neural networks assume all inputs are independent. However, many real-world problems—like predicting the next word in a sentence—depend heavily on previous inputs.
Recurrent Neural Networks (RNNs) address this by maintaining a hidden state that captures past information. Unfortunately, standard RNNs suffer from the vanishing gradient problem, making them ineffective at learning long-term dependencies. This limitation led to the development of more advanced architectures like LSTMs and GRUs.
What Is a GRU (Gated Recurrent Unit)?
A Gated Recurrent Unit (GRU) is a type of recurrent neural network designed to handle sequential data more efficiently than traditional RNNs. Introduced as a simplified alternative to LSTMs, GRUs use gating mechanisms to control the flow of information through the network.
Unlike LSTMs, which use three gates, GRUs rely on just two gates:
1. Update Gate
The update gate determines how much of the past information should be carried forward. It acts as a blend between the previous hidden state and the new candidate state, effectively deciding how much memory to retain.
2. Reset Gate
The reset gate controls how much of the past information to forget. When the reset gate is close to zero, the model ignores previous states, focusing only on current input.
Together, these gates allow GRUs to selectively remember or forget information, making them highly efficient for sequence modeling tasks.
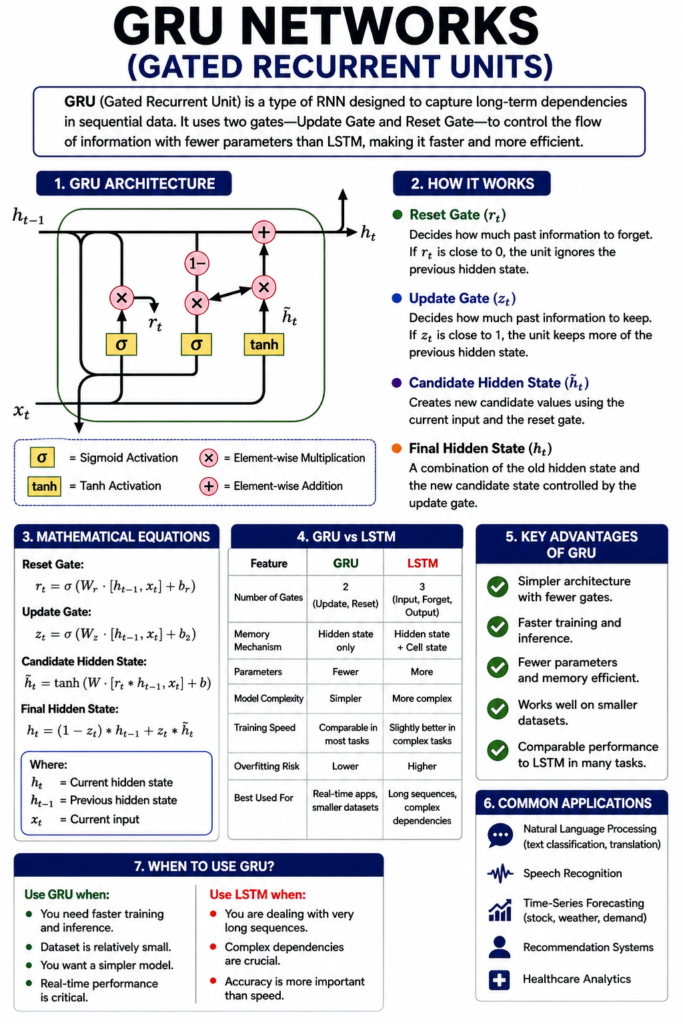
GRU Architecture: How It Works Internally
The internal functioning of a GRU can be summarized through the following steps:
- Compute Reset Gate
Determines whether to forget previous information. - Compute Update Gate
Decides how much past information to keep. - Compute Candidate Hidden State
Generates new memory content. - Compute Final Hidden State
Combines past and new information based on the update gate.
Mathematical Representation
- Reset Gate:
- Update Gate:
- Candidate Hidden State:
- Final Hidden State:
This design ensures that GRUs can maintain long-term dependencies without excessive computational complexity.
Why GRUs Are Powerful: Key Advantages
1. Simpler Architecture
GRUs have fewer gates and parameters compared to LSTMs, making them easier to understand and implement.
2. Faster Training
With fewer parameters, GRUs train faster, which is crucial for large datasets and real-time applications.
3. Better Generalization (Sometimes)
Due to reduced complexity, GRUs are less prone to overfitting in smaller datasets.
4. Comparable Performance
In many real-world tasks, GRUs perform similarly to LSTMs, making them a preferred choice when efficiency matters.
What Is an LSTM? A Quick Overview
Long Short-Term Memory (LSTM) networks were introduced to solve the limitations of traditional RNNs by introducing a more sophisticated memory mechanism.
LSTMs use three gates:
- Input Gate
- Forget Gate
- Output Gate
They also maintain a cell state, which acts as long-term memory, allowing the network to preserve information over long sequences.
While powerful, LSTMs are more complex and computationally expensive than GRUs.
GRU vs LSTM: Detailed Comparison
| Feature | GRU | LSTM |
|---|---|---|
| Number of Gates | 2 (Update, Reset) | 3 (Input, Forget, Output) |
| Memory Mechanism | Hidden state only | Hidden state + Cell state |
| Complexity | Simpler | More complex |
| Training Speed | Faster | Slower |
| Parameters | Fewer | More |
| Performance | Comparable in most tasks | Slightly better in complex tasks |
| Overfitting Risk | Lower | Higher |
| Use Case Suitability | Real-time, smaller datasets | Long sequences, complex dependencies |
When Should You Use GRU Instead of LSTM?
Choosing between GRU and LSTM depends on your problem and constraints:
Use GRU When:
- You need faster training and inference
- Your dataset is relatively small
- You want a simpler model
- Real-time performance is critical
Use LSTM When:
- You are dealing with very long sequences
- Complex dependencies are crucial
- Accuracy is more important than speed
GRU Implementation in Python (Keras Example)
Below is a simple implementation of a GRU model using TensorFlow/Keras:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
# Create model
model = Sequential()
# Add GRU layer
model.add(GRU(64, input_shape=(100, 1), return_sequences=False))
# Output layer
model.add(Dense(1))
# Compile model
model.compile(optimizer='adam', loss='mse')
# Summary
model.summary()Explanation
This model uses a GRU layer with 64 units to process sequential input data of shape (100 timesteps, 1 feature). The GRU layer captures temporal dependencies, and the Dense layer produces the final output. This structure is commonly used in time-series forecasting and sequence prediction tasks.
Real-World Applications of GRUs
GRUs are widely used across industries due to their efficiency and performance:
1. Natural Language Processing (NLP)
GRUs are used for tasks like text classification, sentiment analysis, and machine translation.
2. Speech Recognition
They help process sequential audio data efficiently.
3. Time-Series Forecasting
Applications include stock prediction, weather forecasting, and demand forecasting.
4. Recommendation Systems
GRUs model user behavior sequences for personalized recommendations.
5. Healthcare Analytics
Used in predicting patient outcomes from sequential medical data.
Limitations of GRUs
While GRUs are powerful, they are not perfect:
- May struggle with extremely long sequences compared to LSTMs
- Less expressive than LSTMs due to fewer gates
- Performance differences depend heavily on the dataset
Future of GRUs in Deep Learning
With the rise of Transformer-based models, one might assume RNN-based architectures are becoming obsolete. However, GRUs still hold strong relevance in scenarios where computational efficiency and low latency are critical, such as edge devices and real-time systems.
Moreover, hybrid architectures combining GRUs with attention mechanisms are becoming increasingly popular, offering the best of both worlds—efficiency and contextual understanding.
Conclusion: GRU or LSTM—Which One Wins?
There is no universal winner between GRUs and LSTMs. GRUs provide a streamlined, efficient alternative that performs remarkably well in many tasks, especially when speed and simplicity matter. LSTMs, on the other hand, offer greater flexibility and power for modeling highly complex sequences.
In practice, many data scientists start with GRUs due to their simplicity and only switch to LSTMs if performance improvements are needed.