
Introduction: The Hidden Engine Behind Accurate, Scalable, and Intelligent AI Systems
In the world of machine learning, flashy algorithms and complex models often steal the spotlight—but behind every successful model lies something far more critical: high-quality data. Without the right data, even the most advanced algorithms fail to deliver meaningful results. Data collection is not just the first step in the machine learning pipeline; it is the foundation that determines the accuracy, fairness, and reliability of your entire system.
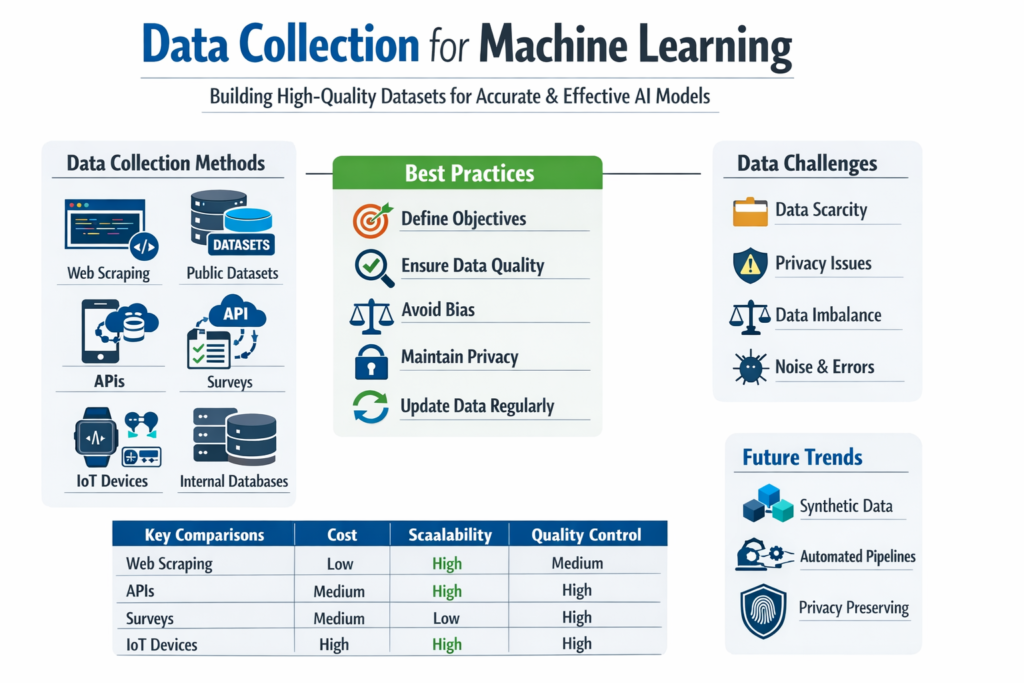
What is Data Collection for Machine Learning?
Data collection for machine learning refers to the process of gathering relevant, high-quality data from various sources to train, validate, and test ML models. This data can be structured (like tables), semi-structured (like JSON files), or unstructured (like images, audio, or text).
The purpose of collecting data is to ensure that machine learning models can learn patterns, relationships, and trends that generalize well to real-world scenarios. Poor data collection leads to biased models, inaccurate predictions, and ultimately, failed deployments.
Why Data Collection is Crucial for ML Success
The performance of any machine learning model is directly proportional to the quality and relevance of the data it is trained on. Even a simple algorithm can outperform a complex one if it is trained on better data.
Key reasons why data collection in Machine Learning matters:
- Accuracy: High-quality data leads to better predictions.
- Generalization: Diverse datasets prevent overfitting.
- Bias Reduction: Properly collected data ensures fairness.
- Scalability: Well-structured datasets support future model improvements.
Types of Data Used in Machine Learning
Understanding the types of data is essential before collecting them.
| Data Type | Description | Examples |
|---|---|---|
| Structured Data | Organized in rows and columns | Excel sheets, SQL databases |
| Unstructured Data | No predefined format | Images, videos, audio |
| Semi-Structured | Partial organization | JSON, XML |
| Time-Series Data | Data collected over time | Stock prices, sensor data |
| Text Data | Natural language content | Tweets, reviews, emails |
Each type requires different collection strategies and preprocessing techniques.
Common Methods of Data Collection for Machine Learning
1. Web Scraping
Web scraping involves extracting data from websites using automated tools or scripts. It is widely used to gather large volumes of data such as product prices, reviews, or news articles.
- Tools: BeautifulSoup, Scrapy, Selenium
- Use cases: E-commerce, sentiment analysis
However, ethical and legal considerations must be followed, including respecting website terms of service.
2. Public Datasets
Public datasets are readily available and are often used for learning, experimentation, and benchmarking.
- Examples: Kaggle datasets, government open data portals
- Advantages: Easy access, no cost
- Limitations: May not fit specific use cases
3. APIs (Application Programming Interfaces)
APIs allow you to collect real-time or historical data from platforms.
- Examples: Twitter API, Google Maps API
- Benefits: Structured, reliable data
- Challenges: Rate limits, authentication
4. Surveys and Questionnaires
Direct data collection from users provides customized and targeted datasets.
- Tools: Google Forms, SurveyMonkey
- Use cases: Market research, behavioral analysis
5. Sensors and IoT Devices
Devices collect real-time data from the environment.
- Examples: Wearables, smart home devices
- Use cases: Healthcare monitoring, predictive maintenance
6. Databases and Internal Systems
Organizations often use their own data stored in databases.
- Examples: CRM systems, ERP systems
- Advantage: Highly relevant and proprietary
7. Data Augmentation
Instead of collecting new data, augmentation creates variations of existing data.
- Examples: Rotating images, adding noise
- Useful for: Deep learning and computer vision
Comparison of Data Collection Methods
| Method | Cost | Scalability | Quality Control | Customization | Use Case |
|---|---|---|---|---|---|
| Web Scraping | Low | High | Medium | Low | Market analysis |
| Public Datasets | Free | Medium | Low | Low | Learning, prototyping |
| APIs | Medium | High | High | Medium | Real-time applications |
| Surveys | Medium | Low | High | High | User-specific insights |
| IoT Devices | High | High | High | High | Real-time monitoring |
| Internal Data | Low | High | High | High | Business intelligence |
Best Practices for Data Collection in Machine Learning
1. Define Clear Objectives
Before collecting data, clearly define what problem you are solving. This helps in identifying what type of data is required and avoids unnecessary data accumulation.
2. Ensure Data Quality
High-quality data should be:
- Accurate
- Complete
- Consistent
- Relevant
Data cleaning is often required after collection, but starting with good data reduces effort significantly.
3. Avoid Bias in Data Collection
Bias in data leads to unfair and unreliable models. Ensure diversity in your dataset by including different groups, conditions, and scenarios.
4. Collect Sufficient Data
Insufficient data leads to poor model performance. However, more data is not always better—relevant data matters more than volume.
5. Maintain Data Privacy and Compliance
Follow regulations such as GDPR or local data protection laws. Ensure user consent and anonymize sensitive information.
6. Use Automation Where Possible
Automating data collection improves efficiency and reduces human error. Tools and pipelines can streamline the process.
7. Label Data Accurately
For supervised learning, labeled data is crucial. Poor labeling leads to incorrect learning patterns.
- Use multiple annotators
- Validate labels through cross-checking
8. Continuously Update Data
Data becomes outdated over time. Regular updates ensure that models remain relevant and accurate.
Challenges in Data Collection
Despite its importance, data collection comes with several challenges:
- Data Scarcity: Lack of sufficient data
- Data Privacy Issues: Legal restrictions
- Data Imbalance: Uneven class distribution
- Noise and Errors: Inaccurate data
- High Costs: Especially for custom datasets
Addressing these challenges requires planning, resources, and continuous monitoring.
The Role of Data Annotation in ML
Data annotation is the process of labeling data to make it understandable for machine learning models. It is especially important in supervised learning.
Examples:
- Labeling images (cat, dog, car)
- Tagging text (positive, negative sentiment)
- Annotating speech
High-quality annotation directly impacts model performance.
Future Trends in Data Collection for ML
The landscape of data collection is evolving rapidly:
- Synthetic Data Generation: Creating artificial datasets
- Crowdsourcing: Using distributed human input
- Automated Data Pipelines: End-to-end data workflows
- Privacy-Preserving Techniques: Federated learning, differential privacy
These innovations aim to make data collection more efficient, scalable, and ethical.
Conclusion
Data collection is not just a preliminary step in machine learning—it is the backbone of every successful AI system. From selecting the right sources to ensuring data quality and ethical compliance, every decision made during data collection directly impacts model performance. By following best practices, leveraging the right tools, and staying aware of challenges, you can build datasets that power robust, scalable, and intelligent machine learning solutions.