
Introduction: Why Feature Engineering Is the Real Game-Changer in Machine Learning
When most people think about machine learning, they immediately imagine complex algorithms, neural networks, or cutting-edge AI systems. However, seasoned data scientists know a crucial truth: even the most sophisticated models fail without well-crafted features. Feature engineering is the silent force that transforms raw data into meaningful signals, enabling models to learn patterns effectively and make accurate predictions. It is often said that better data beats better algorithms—and feature engineering is the bridge that makes this possible. Whether you are a beginner stepping into data science or a professional refining your models, mastering feature engineering can significantly improve your outcomes and give you a competitive edge.
What is Feature Engineering?
Feature engineering is the process of transforming raw data into meaningful input variables (features) that improve the performance of machine learning models. It involves selecting, modifying, and creating new features from existing data to better represent the underlying problem.
In simpler terms, feature engineering helps the model “understand” the data more clearly. Raw data is often noisy, incomplete, or not in a format that algorithms can interpret effectively. By applying domain knowledge, statistical techniques, and data transformations, we can extract useful information that enhances predictive power.
For example, instead of directly using a “date” column, you might extract features such as:
- Day of the week
- Month
- Whether it’s a weekend or a holiday
These derived features often provide more predictive value than the original data.
Why Feature Engineering Matters in Machine Learning
Feature engineering plays a critical role in determining the success of a machine learning model. Even the most advanced algorithms cannot compensate for poor-quality features.
Key Benefits:
- Improves Model Accuracy: Well-engineered features provide clearer patterns for models to learn.
- Reduces Overfitting: Meaningful features reduce noise and irrelevant information.
- Enhances Interpretability: Easier to understand relationships between variables.
- Boosts Training Efficiency: Cleaner data leads to faster convergence.
A model trained on poorly engineered features may produce misleading or inaccurate predictions, while a simpler model with strong features can outperform complex architectures.
Types of Feature Engineering Techniques
Feature engineering consists of several techniques, each serving a specific purpose depending on the dataset and problem type.
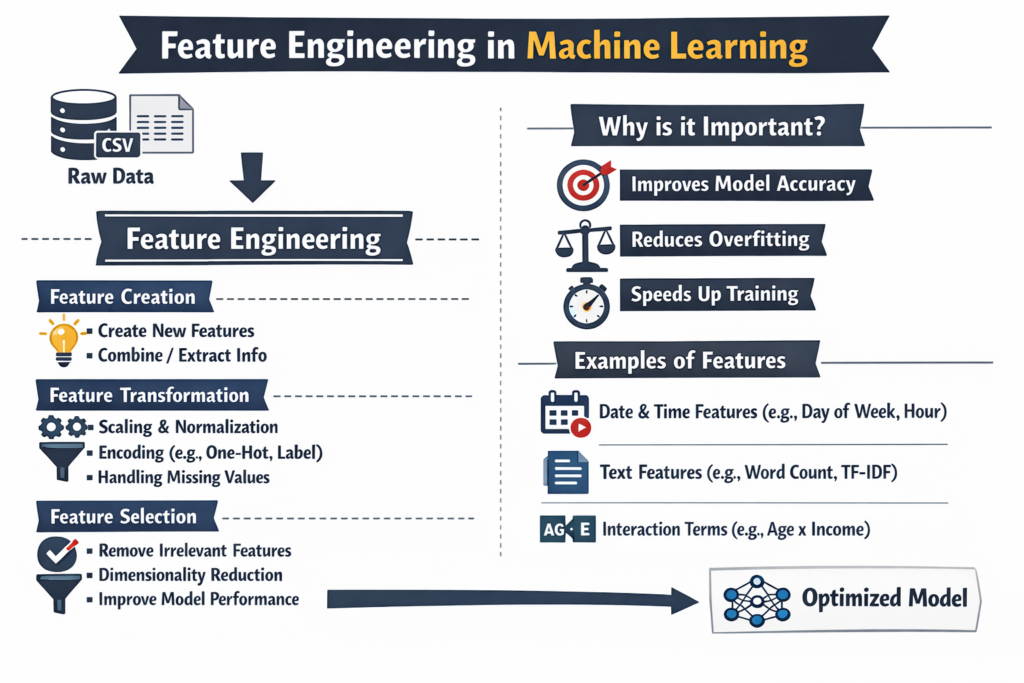
1. Feature Transformation
Feature transformation involves modifying existing features to make them more suitable for modeling.
Examples:
- Log transformation for skewed data
- Scaling (Min-Max, Standardization)
- Normalization
from sklearn.preprocessing import StandardScaler
import pandas as pd
data = pd.DataFrame({'salary': [20000, 30000, 50000, 100000]})
scaler = StandardScaler()
data['scaled_salary'] = scaler.fit_transform(data[['salary']])
print(data)This ensures that features are on a similar scale, which is essential for algorithms like KNN and SVM.
2. Feature Creation
Feature creation involves generating new features from existing ones to capture hidden patterns.
Examples:
- Age = Current Year – Birth Year
- Price per unit = Total price / Quantity
- Interaction features (e.g., height × weight)
df['price_per_unit'] = df['total_price'] / df['quantity']This technique leverages domain knowledge to create meaningful insights.
3. Feature Encoding
Machine learning models cannot process categorical data directly, so encoding is necessary.
Types of Encoding:
- Label Encoding
- One-Hot Encoding
- Target Encoding
import pandas as pd
df = pd.DataFrame({'city': ['Delhi', 'Mumbai', 'Delhi']})
df_encoded = pd.get_dummies(df, columns=['city'])
print(df_encoded)Encoding transforms categorical values into numerical format without losing information.
4. Feature Selection
Feature selection focuses on identifying the most relevant features and removing unnecessary ones.
Methods:
- Filter methods (correlation, chi-square)
- Wrapper methods (recursive feature elimination)
- Embedded methods (Lasso, Ridge)
from sklearn.feature_selection import SelectKBest, f_classif
X_new = SelectKBest(score_func=f_classif, k=2).fit_transform(X, y)Reducing irrelevant features improves model performance and reduces complexity.
5. Handling Missing Values
Missing data can negatively impact model performance if not handled properly.
Techniques:
- Mean/Median Imputation
- Mode Imputation
- Forward/Backward Filling
- Predictive Imputation
df['age'].fillna(df['age'].mean(), inplace=True)Handling missing values ensures data consistency and reliability.
6. Feature Scaling
Scaling ensures that numerical features contribute equally to the model.
Types:
- Min-Max Scaling
- Standardization
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['scaled'] = scaler.fit_transform(df[['value']])Without scaling, features with larger values may dominate the model.
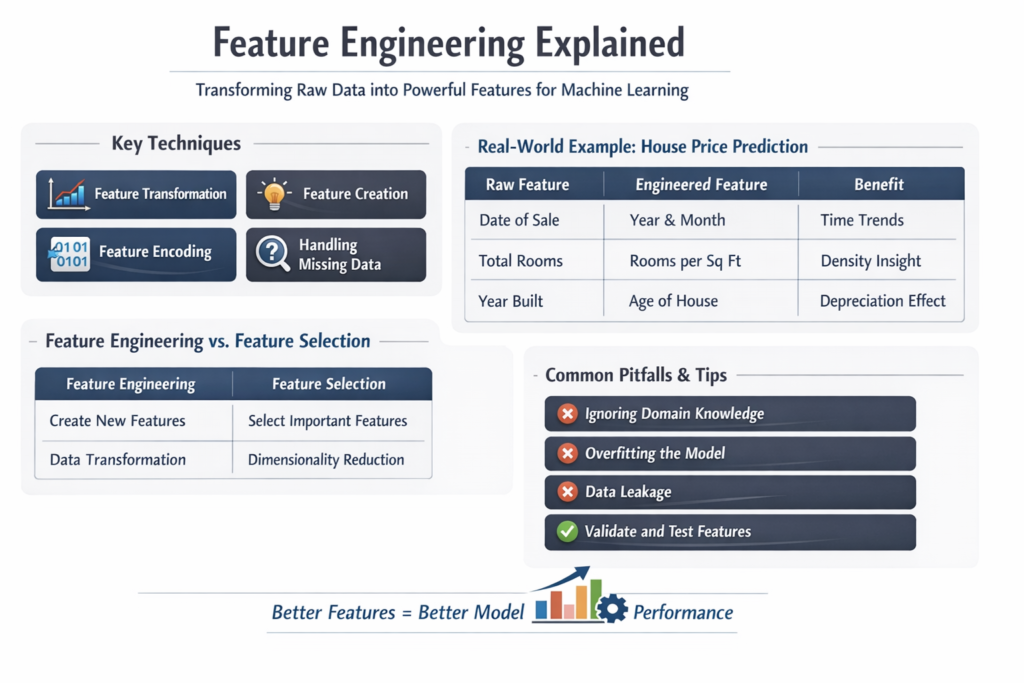
Real-World Example of Feature Engineering
Consider a dataset for predicting house prices.
| Raw Feature | Engineered Feature | Benefit |
|---|---|---|
| Date of sale | Year, Month, Season | Captures time trends |
| Total rooms | Rooms per square foot | Density insight |
| Address | Location cluster | Regional pricing patterns |
| Year built | Age of house | Depreciation effect |
Instead of feeding raw data directly, these engineered features provide more context and predictive strength.
Advanced Feature Engineering Techniques
1. Polynomial Features
These create interaction terms between variables.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)Useful for capturing non-linear relationships.
2. Binning (Discretization)
Continuous variables are grouped into bins.
df['age_group'] = pd.cut(df['age'], bins=[0,18,35,60,100])Helps in simplifying complex relationships.
3. Time-Based Features
Extracting meaningful insights from timestamps.
Examples:
- Hour of the day
- Day of the week
- Seasonal trends
4. Text Feature Engineering
Used in NLP tasks.
Techniques:
- Bag of Words
- TF-IDF
- Word Embeddings
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)Transforms text into numerical representations.
Feature Engineering vs Feature Selection
| Aspect | Feature Engineering | Feature Selection |
| Purpose | Create new features | Select important features |
| Focus | Data transformation | Dimensionality reduction |
| Example | Age from DOB | Removing low-importance columns |
| Impact | Improves signal | Reduces noise |
Both techniques are complementary and often used together.
Common Mistakes in Feature Engineering
- Ignoring Domain Knowledge: Pure statistical transformations may miss real-world context.
- Over-Engineering: Too many features can lead to overfitting.
- Data Leakage: Using future data in training can mislead models.
- Not Validating Features: Always test feature importance and impact.
Avoiding these mistakes ensures robust and reliable models.
Best Practices for Effective Feature Engineering
- Understand the data deeply before transformation
- Use visualization to detect patterns
- Iterate and experiment with different features
- Validate features using cross-validation
- Keep features simple and interpretable
Feature engineering is not a one-time process but an iterative cycle of improvement.
Conclusion: Feature Engineering Is Where Real Intelligence Lies
Feature engineering is one of the most impactful steps in the machine learning pipeline. While algorithms receive much of the attention, it is the quality and relevance of features that truly determine success. By transforming raw data into meaningful representations, feature engineering unlocks hidden patterns and enables models to perform at their best. Whether you are working on predictive analytics, recommendation systems, or deep learning projects, investing time in feature engineering will consistently yield better results than simply switching algorithms.