
Introduction: The Complete Guide to RAG Architecture and How It Improves AI Accuracy
Artificial Intelligence has transformed how businesses, developers, students, and professionals access information. Large Language Models (LLMs) such as ChatGPT, Gemini, Claude, and Llama have demonstrated remarkable capabilities in generating human-like text, answering questions, summarizing documents, and assisting with decision-making. However, despite their impressive performance, these models face a significant challenge: they can generate incorrect, outdated, or fabricated information, a phenomenon commonly known as AI hallucination.
This challenge becomes particularly critical when AI systems are used in domains such as healthcare, finance, law, education, customer support, and enterprise knowledge management. Organizations require AI systems that provide accurate, reliable, and context-aware responses based on real data rather than relying solely on pre-trained knowledge.
This is where Retrieval-Augmented Generation (RAG) emerges as a game-changing solution. RAG combines the reasoning power of Large Language Models with real-time information retrieval mechanisms, enabling AI systems to access external knowledge sources before generating responses. The result is significantly improved accuracy, relevance, transparency, and trustworthiness.
In this comprehensive guide, we will explore RAG architecture, understand how it works, examine its components, advantages, challenges, implementation methods, and future potential.
What is Retrieval-Augmented Generation (RAG)?
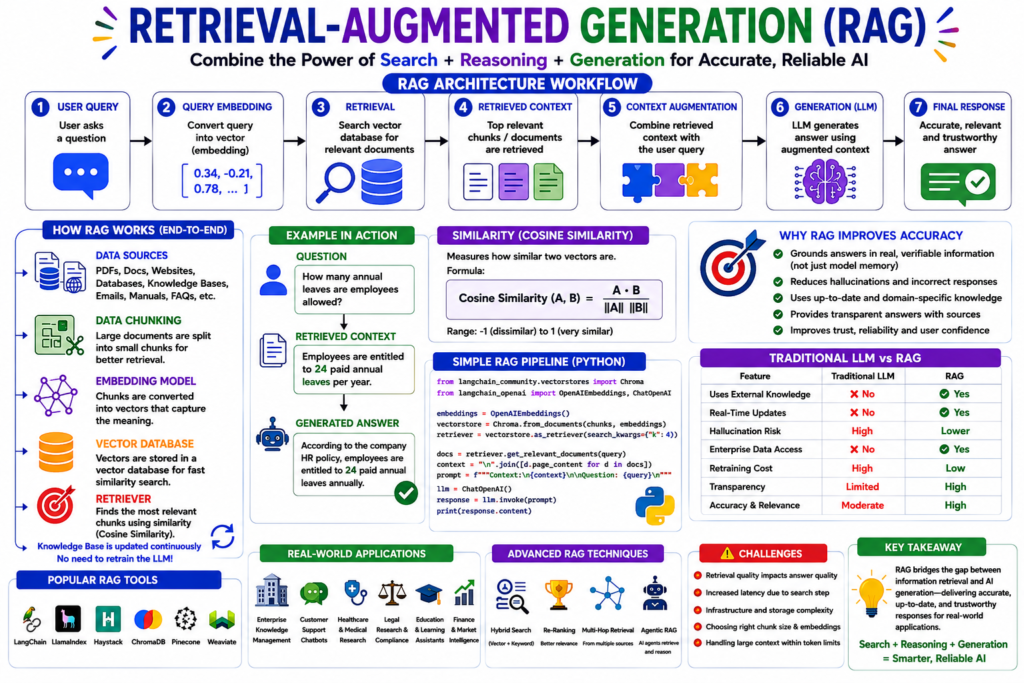
Retrieval-Augmented Generation (RAG) is an AI framework that enhances Large Language Models by allowing them to retrieve relevant information from external data sources before generating responses.
Instead of relying only on information learned during training, a RAG system searches databases, documents, websites, knowledge bases, PDFs, and vector databases to find relevant information for a user’s query. The retrieved information is then provided as context to the language model, which generates a more accurate and contextually relevant answer.
In simple terms:
Traditional LLM = Memory-Based Answering
RAG = Search + Reasoning + Generation
This combination allows AI systems to provide responses based on current and organization-specific knowledge rather than solely depending on static training data.
Why Traditional LLMs Need RAG
Large Language Models are trained on massive datasets containing billions of words. While they possess strong language understanding capabilities, they have several limitations:
Limited Knowledge Cutoff
Models only know information available up to their training date. They cannot automatically learn newly published information.
Hallucinations
LLMs may confidently generate incorrect facts, citations, or explanations.
Lack of Enterprise Knowledge
Organizations possess internal documents, policies, manuals, reports, and proprietary information that public AI models cannot access.
High Retraining Costs
Updating a model by retraining it on new data is expensive, time-consuming, and computationally intensive.
RAG addresses all these challenges by retrieving relevant information dynamically at query time.
Understanding the Core RAG Architecture
A typical RAG architecture consists of several interconnected components working together.
RAG Architecture Workflow
User Query
│
▼
Query Embedding
│
▼
Vector Database Search
│
▼
Relevant Documents Retrieved
│
▼
Context Augmentation
│
▼
Large Language Model
│
▼
Generated Response
The architecture follows a retrieval-first approach, ensuring the AI model receives accurate contextual information before generating an answer.
Key Components of RAG Architecture
1. Data Sources
Data sources are repositories containing information that the AI system can access.
Examples include:
- PDFs
- Research papers
- Company documentation
- Databases
- Websites
- CRM systems
- Product catalogs
- Knowledge bases
- FAQs
These documents serve as the foundation of the retrieval system.
2. Data Chunking
Large documents are divided into smaller segments called chunks.
For example:
A 100-page PDF may be divided into hundreds of smaller paragraphs or sections.
Chunking improves retrieval precision because searching smaller text segments is more efficient than searching entire documents.
Example:
Document:
Introduction to Machine Learning
Chunk 1:
Definition of Machine Learning
Chunk 2:
Types of Machine Learning
Chunk 3:
Applications of Machine Learning
3. Embedding Model
Embeddings convert text into numerical vectors.
These vectors capture semantic meaning, allowing machines to understand relationships between words and concepts.
Example:
"Artificial Intelligence"
→ [0.34, 0.92, -0.12, ...]
Popular embedding models include:
- OpenAI Embeddings
- Sentence Transformers
- BGE Embeddings
- Cohere Embeddings
- Instructor XL
4. Vector Database
The generated embeddings are stored in vector databases.
Popular vector databases include:
| Vector Database | Open Source | Cloud Support | Scalability |
|---|---|---|---|
| Pinecone | No | Yes | High |
| ChromaDB | Yes | Limited | Medium |
| Weaviate | Yes | Yes | High |
| FAISS | Yes | Local | High |
| Milvus | Yes | Yes | Very High |
The vector database enables similarity search.
5. Retriever
The retriever searches the vector database to find documents most relevant to the user query.
The query is converted into an embedding and compared against stored vectors.
Similarity metrics commonly used include:
- Cosine Similarity
- Euclidean Distance
- Dot Product Similarity
Cosine Similarity Formula:
\text{Cosine Similarity}(A,B)=\frac{A\cdot B}{|A||B|}
A higher similarity score indicates a stronger semantic relationship between vectors.
6. Context Augmentation
The retrieved documents are combined with the user’s query.
Example:
Question:
What is Retrieval-Augmented Generation?
Retrieved Context:
RAG combines information retrieval with language generation.
Augmented Prompt:
Using the retrieved context, explain Retrieval-Augmented Generation.
This enriched prompt provides factual grounding for the model.
7. Generator (LLM)
The language model receives the augmented context and generates a final response.
Popular generators include:
- GPT-4
- GPT-5
- Claude
- Gemini
- Llama
- Mistral
Since the model works with retrieved evidence, answers become more reliable and accurate.
Step-by-Step Example of RAG in Action
Imagine a company’s HR chatbot.
User Question
How many annual leaves are employees allowed?
Retrieval Process
The system searches internal HR policies and retrieves:
Employees are entitled to 24 paid annual leaves per year.
Generation Process
The LLM generates:
According to the company's HR policy, employees are entitled to 24 paid annual leaves annually.
Without RAG, the model might guess or provide generic leave policies.
With RAG, the answer comes directly from organizational knowledge.
How RAG Improves Accuracy
Reduces Hallucinations
The model relies on retrieved evidence rather than guessing.
Provides Current Information
Data sources can be updated continuously without retraining the model.
Improves Domain Expertise
RAG enables AI systems to answer questions about specialized industries and internal company knowledge.
Enhances Trust
Users can verify responses against retrieved documents.
Supports Explainability
Organizations can trace answers back to source documents.
Traditional LLM vs RAG
| Feature | Traditional LLM | RAG |
|---|---|---|
| Uses External Knowledge | No | Yes |
| Real-Time Updates | No | Yes |
| Hallucination Risk | High | Lower |
| Enterprise Data Access | No | Yes |
| Training Cost | High | Low |
| Transparency | Limited | High |
| Context Awareness | Moderate | High |
| Scalability | Moderate | High |
The table clearly shows why RAG has become the preferred architecture for enterprise AI applications.
Python Example of a Simple RAG Pipeline
Using LangChain and ChromaDB:
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
loader = TextLoader("knowledge_base.txt")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
chunks = splitter.split_documents(documents)
vectorstore = Chroma.from_documents(
chunks,
OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
query = "What is Retrieval Augmented Generation?"
docs = retriever.get_relevant_documents(query)
llm = ChatOpenAI()
context = "\n".join([doc.page_content for doc in docs])
prompt = f"""
Context:
{context}
Question:
{query}
"""
response = llm.predict(prompt)
print(response)
This example demonstrates the fundamental workflow of a RAG application.
Popular RAG Frameworks and Tools
Several frameworks simplify RAG implementation.
| Framework | Purpose |
|---|---|
| LangChain | End-to-end RAG development |
| LlamaIndex | Data ingestion and retrieval |
| Haystack | Search and QA systems |
| DSPy | Optimized AI pipelines |
| Semantic Kernel | Enterprise AI orchestration |
| LangGraph | Agentic workflows |
These tools significantly reduce development complexity.
Advanced RAG Techniques
As RAG systems evolve, advanced architectures are emerging.
Hybrid Search
Combines:
- Vector Search
- Keyword Search
This improves retrieval quality.
Re-Ranking
Retrieved documents are re-scored using specialized ranking models.
Benefits:
- Better relevance
- Improved accuracy
- Enhanced user experience
Multi-Hop Retrieval
The system retrieves information from multiple sources before generating answers.
Useful for:
- Research assistants
- Legal systems
- Medical applications
Agentic RAG
AI agents dynamically decide:
- What information to retrieve
- Which tools to use
- How to reason over retrieved data
Agentic RAG is expected to dominate next-generation enterprise AI systems.
Real-World Applications of RAG
Enterprise Knowledge Management
Employees can search company documentation through conversational AI.
Customer Support
Chatbots answer customer queries using product manuals and support databases.
Healthcare
Medical assistants retrieve information from clinical guidelines and research papers.
Legal Industry
Lawyers can search regulations, contracts, and legal precedents.
Education
Students receive answers from textbooks, lecture notes, and other academic resources.
Financial Services
Analysts can query reports, filings, and market intelligence databases.
Advantages of RAG
Higher Accuracy
Responses are grounded in retrieved knowledge.
Lower Hallucination Rate
Factual evidence improves reliability.
Real-Time Updates
Knowledge bases can be updated instantly.
Cost Effective
No need for frequent model retraining.
Better Explainability
Responses can reference source documents.
Enterprise Readiness
Supports private and proprietary information.
Disadvantages of RAG
Retrieval Errors
Poor retrieval leads to poor answers.
Latency
Additional search operations increase response time.
Infrastructure Complexity
Requires databases, embeddings, indexing, and monitoring.
Storage Costs
Large vector databases consume storage resources.
Context Limitations
Too much retrieved content may exceed model context windows.
Organizations must carefully design retrieval pipelines to maximize performance.
Challenges in Building Effective RAG Systems
Developers often encounter several challenges:
- Selecting optimal chunk sizes
- Managing document updates
- Improving retrieval precision
- Reducing duplicate content
- Maintaining low latency
- Handling multilingual data
- Evaluating response quality
Continuous monitoring and optimization are essential for production-grade RAG systems.
The Future of Retrieval-Augmented Generation
The future of AI is increasingly moving toward retrieval-centric architectures.
Several trends are shaping the next generation of RAG:
Multimodal RAG
Retrieval from:
- Text
- Images
- Videos
- Audio
- Documents
Agentic AI Systems
Autonomous AI agents will use RAG to gather evidence before making decisions.
Graph-Based RAG
Knowledge graphs will improve reasoning across interconnected information.
Personalized RAG
AI systems will retrieve user-specific information to generate personalized responses.
Enterprise AI Ecosystems
RAG will become the backbone of organizational AI platforms, enabling secure and accurate access to company knowledge.
As AI adoption accelerates worldwide, RAG is likely to become a standard architectural pattern for intelligent applications.
Conclusion
Retrieval-Augmented Generation (RAG) represents one of the most significant advancements in modern artificial intelligence. By combining information retrieval with large language model generation, RAG overcomes many limitations of traditional LLMs, including hallucinations, outdated knowledge, and lack of access to enterprise-specific information.
The architecture works by retrieving relevant information from external sources, augmenting user queries with contextual knowledge, and then generating responses grounded in factual evidence. This approach dramatically improves accuracy, reliability, explainability, and user trust.
Whether you are a student exploring AI concepts, a developer building intelligent applications, or an enterprise seeking scalable AI solutions, understanding RAG is becoming increasingly important. As technologies such as Agentic AI, multimodal systems, and knowledge graphs continue to evolve, Retrieval-Augmented Generation will remain a foundational component of next-generation AI systems.