
Introduction: Why Vector Databases Are Powering the AI Revolution
Generative AI has transformed how businesses, developers, students, and professionals interact with information. From AI chatbots and intelligent search assistants to recommendation engines and document question-answering systems, one hidden technology powers many of these breakthroughs: vector databases.
Traditional databases are excellent at storing structured information like names, IDs, transactions, and numbers. But modern AI systems need something fundamentally different. They need to understand the meaning, context, similarities, and relationships among pieces of data. This is where vector databases enter the picture.
If you have ever wondered how ChatGPT-like systems retrieve relevant information instantly, how semantic search understands your intent instead of exact keywords, or how recommendation systems know what you may like next, the answer often lies in vector search.
In this comprehensive guide, we will explore vector databases, Approximate Nearest Neighbor (ANN) search, their role in Generative AI, practical Python implementation, best practices, industry applications, and common pitfalls.
What Is a Vector Database?
A vector database is a specialized database designed to store, index, and search high-dimensional numerical representations called vectors or embeddings. Embeddings are mathematical representations of data such as:
- Text
- Images
- Audio
- Video
- Code
- Documents
Instead of storing raw text meaningfully for semantic search, AI converts data into vectors.
For example:
Text:
“Artificial Intelligence is transforming healthcare.”
May become:
[0.234, -0.782, 1.034, 0.665, -0.192, ...]This numerical representation captures semantic meaning. Similar meanings create nearby vectors.
Example:
- “AI in medicine”
- “Artificial intelligence for healthcare”
These may have different words but similar embeddings. That is the core magic.
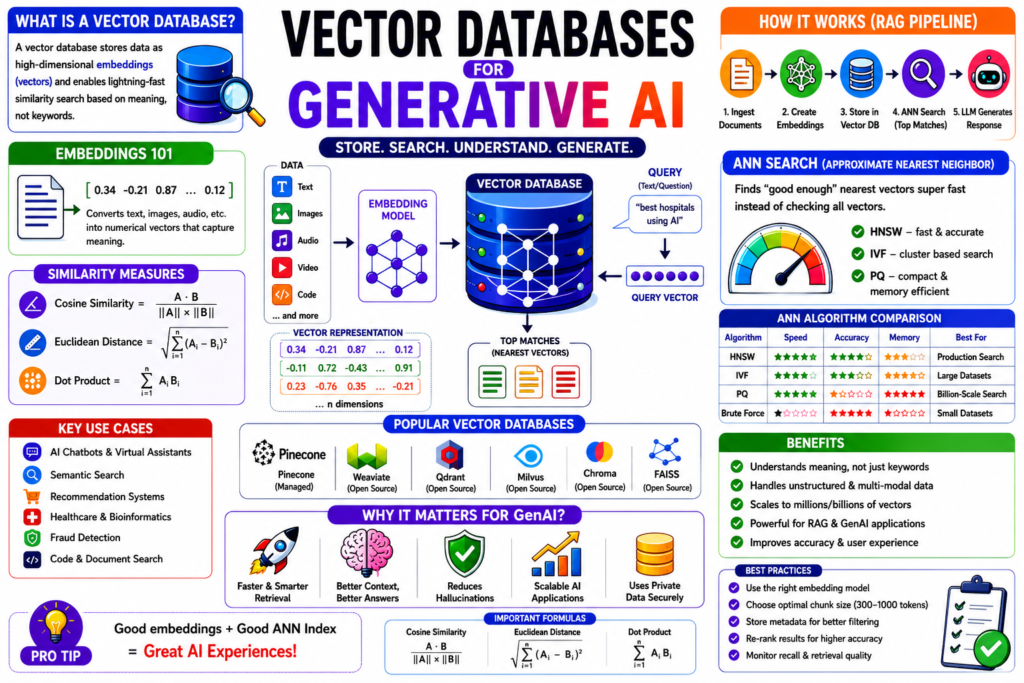
Why Traditional Databases Are Not Enough
Traditional relational databases like MySQL or PostgreSQL excel at exact matching.
Example:
SELECT * FROM articles
WHERE topic = 'AI';But what if the user asks:
“How is machine learning helping hospitals?”
A keyword search may fail if the exact words don’t exist.
Vector databases solve this by finding semantically similar content instead of exact matches.
| Traditional Database | Vector Database |
|---|---|
| Exact keyword match | Semantic similarity |
| Structured data | Unstructured data |
| SQL filtering | Vector similarity search |
| Numeric/string comparisons | Embedding comparisons |
| Slower for similarity search | Optimized for nearest-neighbor retrieval |
Understanding Embeddings: The Foundation of Vector Search
Embeddings are dense numerical vectors generated by machine learning models. These models convert content into mathematical space.
Examples:
- OpenAI embedding models
- Sentence Transformers
- BERT
- Cohere embeddings
- Hugging Face models
If two concepts are similar, their vectors lie close together. Example:
| Text | Simplified Vector |
|---|---|
| Cat | [0.2, 0.8, 0.4] |
| Kitten | [0.21, 0.79, 0.42] |
| Car | [0.9, 0.1, 0.3] |
“Cat” and “Kitten” are close.
“Car” is far away.
This enables semantic intelligence.
Mathematical Foundation of Similarity Search
Vector similarity depends on mathematical distance metrics.
1. Cosine Similarity
Measures angle between vectors.
Formula:
Where:
- A⋅B = dot product
- ∣∣A∣∣ = vector magnitude
Higher similarity means vectors are semantically closer.
Example Python:
import numpy as np
A = np.array([1, 2, 3])
B = np.array([2, 4, 6])
cos_sim = np.dot(A, B) / (np.linalg.norm(A) * np.linalg.norm(B))
print(cos_sim)Output:
1.0Perfect similarity.
2. Euclidean Distance
Measures straight-line distance.
Formula:
Lower distance means greater similarity.
Example:
from scipy.spatial.distance import euclidean
A = [1, 2]
B = [4, 6]
print(euclidean(A, B))3. Dot Product Similarity
Formula:
Often faster in optimized vector systems.
What Is ANN Search (Approximate Nearest Neighbor)?
Finding the nearest vectors among millions or billions is computationally expensive. Exact search compares the query vector against every stored vector.
Complexity:
This becomes impractical at scale. Approximate Nearest Neighbor (ANN) solves this. Instead of checking every vector, ANN finds “good enough” nearest matches dramatically faster. Think of it like:
Exact Search: Reading every page in a library.
ANN Search: Using a highly intelligent map.
Popular ANN Algorithms
One of the most widely used ANN algorithms.
Features:
- Extremely fast retrieval
- High accuracy
- Graph-based indexing
- Excellent scalability
Used in:
- Pinecone
- Weaviate
- Qdrant
- FAISS
Best for production AI systems.
IVF (Inverted File Index)
Clusters vectors into partitions.
Search process:
- Find relevant cluster
- Search only inside it
Benefits:
- Faster search
- Lower compute
Tradeoff:
May miss exact nearest neighbors.
PQ (Product Quantization)
Compresses vectors.
Benefits:
- Lower memory usage
- Faster search
Useful for:
Massive vector collections.
ANN Algorithm Comparison
| Algorithm | Speed | Accuracy | Memory Usage | Best Use Case |
|---|---|---|---|---|
| HNSW | Very High | High | Medium | Production search |
| IVF | High | Medium | Medium | Large datasets |
| PQ | Very High | Lower | Low | Billion-scale search |
| Brute Force | Slow | Perfect | High | Small datasets |
How Vector Databases Work
A vector database pipeline typically follows:
Step 1: Data Ingestion
Raw content enters system:
- PDFs
- Websites
- Text documents
- Product descriptions
- Support tickets
Step 2: Embedding Generation
AI converts content into vectors.
Example:
text → embedding model → vectorStep 3: Indexing
Vectors are indexed using ANN structures.
Examples:
- HNSW
- IVF
- PQ
Step 4: Query Vectorization
User query becomes embedding.
Example:
"best hospitals using AI"converted into vector.
Step 5: Similarity Search
Database retrieves nearest vectors.
Step 6: Response Generation
Retrieved context goes to LLM. LLM generates intelligent response.
Vector Database Architecture
User Query
↓
Embedding Model
↓
Vector Representation
↓
ANN Search Index
↓
Nearest Documents
↓
LLM Prompt Context
↓
Generated ResponseThis architecture powers Retrieval-Augmented Generation (RAG).
Vector Databases in Generative AI (GenAI)
Generative AI models do not always know your private business data.
Example:
A company chatbot must answer from:
- internal policies
- HR documents
- support manuals
- product documentation
LLMs alone cannot reliably memorize this. Vector databases solve this using retrieval.
Retrieval-Augmented Generation (RAG)
RAG combines:
- Retrieval
- Vector search
- Large Language Models
Workflow:
- Store documents in vector DB
- Convert user query to embedding
- Retrieve relevant chunks
- Send chunks to LLM
- Generate grounded answer
Benefits:
- Reduced hallucinations
- Fresh knowledge
- Domain-specific responses
- Lower retraining cost
Popular Vector Databases
Comparison Table
| Database | Open Source | Managed Cloud | Best For |
|---|---|---|---|
| Pinecone | No | Yes | Enterprise GenAI |
| Weaviate | Yes | Yes | Semantic applications |
| Qdrant | Yes | Yes | Fast production systems |
| Milvus | Yes | Yes | Large-scale AI search |
| Chroma | Yes | Limited | Prototyping |
| FAISS | Yes | No | Local experimentation |
Python Example: Using ChromaDB
Install:
pip install chromadb sentence-transformersCode:
import chromadb
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
docs = [
"AI helps doctors diagnose disease.",
"Vector databases power semantic search.",
"Machine learning improves recommendation systems."
]
embeddings = model.encode(docs)
client = chromadb.Client()
collection = client.create_collection("articles")
for i, emb in enumerate(embeddings):
collection.add(
ids=[str(i)],
embeddings=[emb.tolist()],
documents=[docs[i]]
)
query = "How does AI improve healthcare?"
query_embedding = model.encode([query])[0]
results = collection.query(
query_embeddings=[query_embedding.tolist()],
n_results=2
)
print(results)Real Industry Use Cases
1. AI Chatbots
Customer support assistants retrieve accurate knowledge instantly.
Examples:
- e-commerce bots
- healthcare assistants
- banking support
2. Semantic Search Engines
Instead of keyword matching:
"best budget smartphones"returns meaning-based results.
Useful in:
- ecommerce
- enterprise search
- legal discovery
3. Recommendation Systems
Find similar products/users.
Applications:
- Netflix recommendations
- Amazon product discovery
- music recommendations
4. Fraud Detection
Similar anomaly patterns can be retrieved quickly.
Financial AI systems use vector similarity.
5. Code Search
Developer tools retrieve relevant code snippets semantically.
Examples:
- GitHub AI assistants
- documentation copilots
6. Healthcare Knowledge Retrieval
Medical assistants search:
- journals
- diagnoses
- treatment protocols
Safely contextualized answers improve workflows.
Advantages of Vector Databases
Fast Semantic Search
ANN indexing makes retrieval extremely fast.
Scalable AI Infrastructure
Handles millions or billions of embeddings.
Better User Experience
Understands intent, not just keywords.
GenAI Integration
Critical for RAG pipelines.
Multi-modal Support
Supports:
- text
- image
- audio
- video
Disadvantages and Challenges
High Memory Usage
Embeddings consume significant storage.
Approximation Tradeoff
ANN may miss exact neighbors.
Embedding Quality Dependency
Poor embeddings = poor search.
Complex Tuning
Requires tuning:
- index parameters
- chunk size
- embedding model
- metadata filters
Best Practices
Choose the Right Embedding Model
Domain matters.
Examples:
- legal embeddings
- healthcare embeddings
- code embeddings
Chunk Documents Properly
Too large: poor relevance
Too small: loss of context
Good range:
300–1000 tokensStore Metadata
Include:
- source
- timestamp
- author
- document type
Improves filtering.
Re-rank Results
ANN retrieval + re-ranking improves precision.
Monitor Recall
Track retrieval quality continuously.
Common Mistakes Beginners Make
Using Keyword Search Expectations
Semantic search behaves differently.
Ignoring Chunk Overlap
Context fragmentation hurts accuracy.
Selecting Wrong Similarity Metric
Cosine vs Euclidean matters.
No Metadata Filtering
Leads to noisy retrieval.
Overstuffing LLM Context
Too many irrelevant chunks reduce answer quality.
Vector Databases vs Traditional Search Engines
| Feature | Vector DB | Elasticsearch |
|---|---|---|
| Semantic search | Excellent | Limited |
| Keyword search | Moderate | Excellent |
| GenAI integration | Excellent | Moderate |
| ANN indexing | Native | Partial |
| Embedding support | Native | Limited |
Future of Vector Databases
The future includes:
- hybrid search
- multimodal AI retrieval
- memory-enabled AI agents
- personalized AI assistants
- enterprise knowledge copilots
As AI systems become context-aware, vector databases will become infrastructure essentials.
Final Thoughts
Vector databases are not just another database trend. They are foundational infrastructure for modern AI applications. If LLMs are the brains of Generative AI, vector databases are the memory systems.
Understanding embeddings, ANN search, and RAG architecture gives developers a major advantage in building scalable, intelligent AI products.