
— The Hidden Engine Powering Language, Time-Series, and Sequential Intelligence
Introduction: Why Machines Struggle with Sequences—and How RNNs Solve It
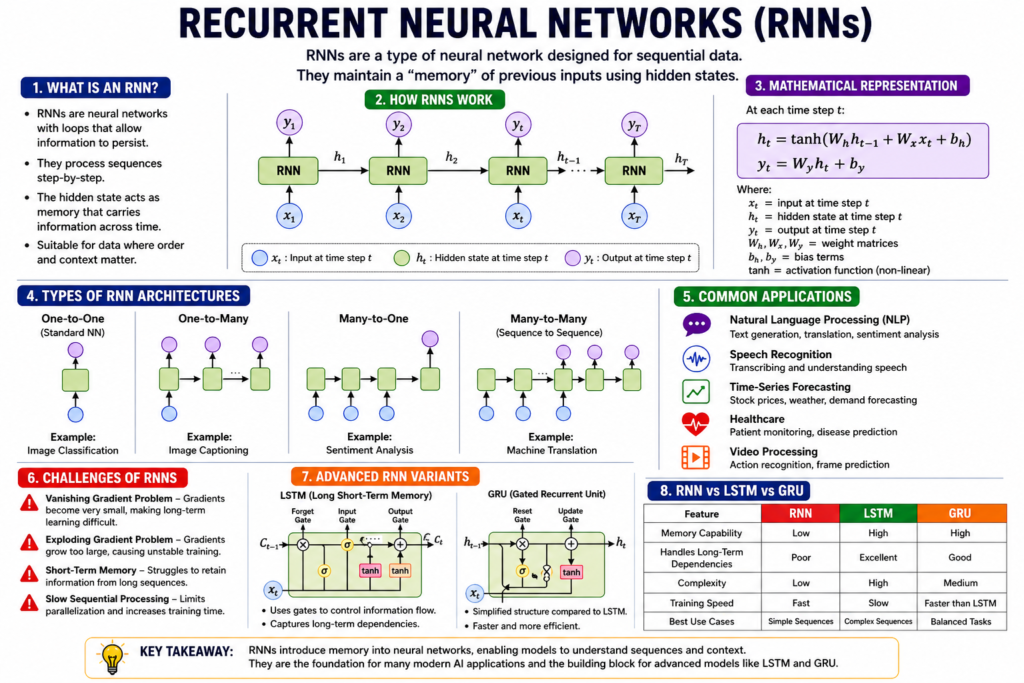
Imagine trying to understand a sentence where you forget every word you just read. That’s exactly how traditional neural networks behave—they process inputs independently, with no memory of what came before. This limitation becomes a major obstacle when working with sequential data like text, speech, stock prices, or sensor signals, where context is everything.
Recurrent Neural Networks (RNNs) were designed to overcome this fundamental gap. They introduce the concept of memory into neural networks, allowing models to retain and use past information while processing current input. This makes them especially powerful for tasks where order, timing, and dependencies matter. From predicting the next word in a sentence to analyzing time-series trends, RNNs have played a foundational role in advancing machine learning for sequential data.
In this article, we will explore what RNNs are, how they work, why they are important, and where they are used. We will also look at their limitations and how modern architectures evolved from them.
What is a Recurrent Neural Network (RNN)?
A Recurrent Neural Network is a type of artificial neural network designed specifically for sequential data. Unlike traditional feedforward networks, RNNs have loops that allow information to persist across time steps.
This means that at any given point, the network considers not only the current input but also the previous inputs it has seen. This “memory” is stored in a hidden state, which gets updated at each step.
Key Idea
An RNN processes data step-by-step, maintaining a running summary of past inputs.
Why Sequential Data Requires Special Treatment
Sequential data differs from standard datasets because:
- Order matters (e.g., “dog bites man” vs. “man bites dog”)
- Context influences meaning
- Dependencies can span multiple time steps
Examples of sequential data include:
- Natural language (sentences, paragraphs)
- Time-series (stock prices, weather data)
- Audio signals (speech recognition)
- Video frames
Traditional neural networks treat each input independently, making them unsuitable for these tasks. RNNs address this by maintaining context.
How RNNs Work: Step-by-Step Explanation
At each time step t, an RNN performs the following:
- Takes input
- Combines it with the previous hidden state
- Produces a new hidden state
- Optionally generates an output
Mathematical Representation
Where:
- : current hidden state
- : input at time step t
- : weights
- : bias
This recursive structure allows information to flow across time.
Understanding the “Memory” in RNNs
The hidden state acts as memory. It captures:
- Past inputs
- Contextual relationships
- Temporal dependencies
However, this memory is not perfect. It tends to focus more on recent inputs and struggles with long-term dependencies—a limitation we will explore later.
Types of RNN Architectures
RNNs can be structured in different ways depending on input-output relationships:
1. One-to-One
- Standard neural network
- Example: Image classification
2. One-to-Many
- Single input, multiple outputs
- Example: Image captioning
3. Many-to-One
- Multiple inputs, single output
- Example: Sentiment analysis
4. Many-to-Many
- Sequence input and output
- Example: Language translation
RNN vs Traditional Neural Networks
| Feature | Traditional Neural Network | Recurrent Neural Network |
|---|---|---|
| Data Handling | Independent inputs | Sequential inputs |
| Memory | No memory | Maintains hidden state |
| Context Awareness | None | High |
| Use Cases | Image classification | NLP, time-series |
| Complexity | Lower | Higher |
This comparison highlights why RNNs are essential when dealing with temporal or ordered data.
Practical Example: Predicting the Next Word
Consider the sentence:
“The sky is ___”
An RNN processes each word sequentially:
- Input: “The” → updates state
- Input: “sky” → refines context
- Input: “is” → predicts next word
Based on learned patterns, it may predict:
- “blue”
- “clear”
This prediction depends heavily on prior context, which RNNs capture effectively.
Simple Python Implementation of an RNN
Below is a basic example using TensorFlow/Keras:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense# Sample data
X = np.array([[1, 2, 3], [2, 3, 4], [3, 4, 5]])
y = np.array([4, 5, 6])# Reshape for RNN [samples, timesteps, features]
X = X.reshape((X.shape[0], X.shape[1], 1))# Build model
model = Sequential()
model.add(SimpleRNN(50, activation='tanh', input_shape=(3, 1)))
model.add(Dense(1))model.compile(optimizer='adam', loss='mse')# Train model
model.fit(X, y, epochs=200, verbose=0)# Predict
print(model.predict(X))
This simple example demonstrates how RNNs can learn patterns in sequences.
Applications of RNNs in the Real World
RNNs have been widely used across industries:
1. Natural Language Processing (NLP)
- Text generation
- Machine translation
- Sentiment analysis
2. Speech Recognition
- Voice assistants
- Audio transcription
3. Time-Series Forecasting
- Stock price prediction
- Demand forecasting
4. Healthcare
- Patient monitoring
- Disease prediction
5. Video Processing
- Action recognition
- Frame prediction
Limitations of RNNs
Despite their usefulness, RNNs have several limitations:
1. Vanishing Gradient Problem
Gradients shrink during backpropagation, making it hard to learn long-term dependencies.
2. Exploding Gradient Problem
Gradients grow excessively, leading to unstable training.
3. Short-Term Memory
RNNs struggle to retain information over long sequences.
4. Slow Training
Sequential processing limits parallelization.
Solutions: Advanced Variants of RNNs
To overcome these issues, improved architectures were developed:
1. Long Short-Term Memory (LSTM)
- Uses gates to control memory
- Retains long-term dependencies
2. Gated Recurrent Unit (GRU)
- Simplified version of LSTM
- Faster and efficient
RNN vs LSTM vs GRU: Comparison Table
| Feature | RNN | LSTM | GRU |
|---|---|---|---|
| Memory Handling | Weak | Strong | Strong |
| Complexity | Low | High | Medium |
| Training Speed | Fast | Slower | Faster than LSTM |
| Long-Term Dependencies | Poor | Excellent | Good |
| Use Case | Simple sequences | Complex sequences | Balanced tasks |
Why RNNs Still Matter Today
Although newer models like Transformers dominate modern NLP, RNNs still hold importance because:
- They are conceptually simple
- Useful for smaller datasets
- Efficient for certain real-time tasks
- Foundational for understanding sequence models
Learning RNNs helps build a strong base for advanced architectures.
When Should You Use RNNs?
RNNs are suitable when:
- Data is sequential
- Context matters
- Dependencies exist across time
However, for very long sequences, LSTMs or Transformers may be better choices.
Conclusion: The Role of RNNs in Modern AI
Recurrent Neural Networks marked a turning point in machine learning by introducing memory into neural architectures. They made it possible for models to understand sequences, enabling breakthroughs in language processing, speech recognition, and time-series forecasting.
While newer models have surpassed them in many applications, RNNs remain a critical stepping stone in the evolution of deep learning. Understanding how they work provides valuable insight into how machines process time-dependent data and sets the stage for mastering more advanced architectures.