
Introduction
When you ask ChatGPT a question, search Google, translate text online, or use a sentiment analysis model, something fundamental happens before artificial intelligence understands your words.
Your beautifully written sentence gets broken into smaller pieces.
These pieces are called tokens.
This process—known as tokenization—is one of the most critical steps in Natural Language Processing (NLP). Without tokenization, machines cannot process human language efficiently.
Imagine giving a machine this sentence:
“Artificial Intelligence is transforming healthcare rapidly.”
Humans instantly understand it.
Machines do not.
To an AI model, this sentence must first become structured units like:
["Artificial", "Intelligence", "is", "transforming", "healthcare", "rapidly"]Or sometimes:
["Art", "ificial", "Intelligence", "transform", "ing"]Or even:
["A", "r", "t", "i", "f", "i", "c", "i", "a", "l"]Different NLP systems tokenize differently depending on the application.
Tokenization may sound simple, but it directly impacts:
- Model accuracy
- Computational cost
- Training efficiency
- Language understanding
- Context retention
- AI response quality
This guide explains how tokenization works, why it matters, practical use cases, Python implementation, formulas, comparison tables, advantages, limitations, and best practices.
What is Tokenization in NLP?
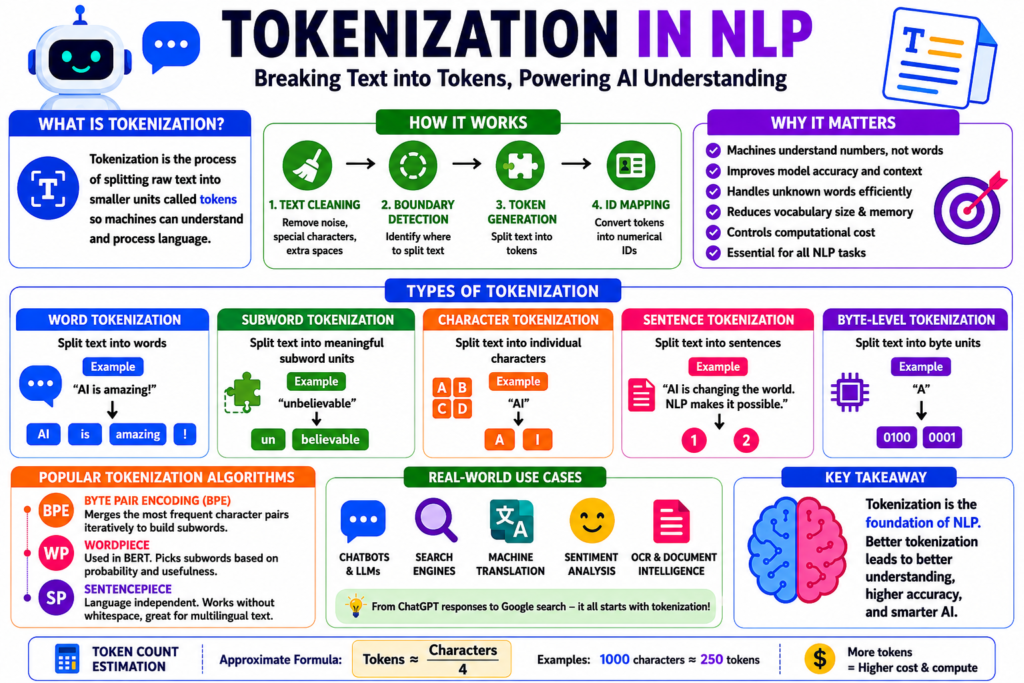
Tokenization is the process of splitting raw text into smaller units called tokens so machines can process language computationally.
A token can be:
- A word
- A subword
- A character
- A sentence
- A punctuation symbol
- A special encoding unit
Example:
Input:
"Machine learning is amazing!"Word tokens:
["Machine", "learning", "is", "amazing"]Character tokens:
["M", "a", "c", "h", "i", "n", "e"]Subword tokens:
["Machine", "learn", "ing", "amazing"]Tokenization converts unstructured text into machine-readable structured data.
Why Tokenization Matters in NLP
1. Machines Cannot Understand Raw Human Language
Computers operate on numbers, not human words.
Before processing text, language must be transformed into machine-compatible units.
Pipeline:
Raw Text → Tokenization → Numerical Encoding → Model ProcessingWithout tokenization, NLP models cannot function.
2. Improves Model Accuracy
Good tokenization preserves meaning.
Bad tokenization can destroy context.
Example:
Sentence:
"unbelievable"Bad split:
["un", "bel", "iev", "able"]Better split:
["un", "believable"]Meaning preservation leads to better predictions.
3. Handles Unknown Words Efficiently
Traditional word tokenization struggles with unseen vocabulary.
Example:
cryptoeconomicsIf absent from vocabulary:
Old systems:
[UNK]Modern tokenizers:
["crypto", "economics"]This improves flexibility dramatically.
4. Reduces Vocabulary Explosion
Without smart tokenization, every unique word needs storage.
Example:
Words:
- run
- running
- runner
- rerun
- runs
Word tokenization treats each as separate entries.
Subword tokenization reuses fragments:
run + ning
run + ner
re + runThis reduces memory requirements.
5. Controls Computational Cost
Large token counts increase:
- API cost
- latency
- memory usage
- GPU requirements
For LLMs, token efficiency matters enormously.
Example:
A 1000-word article may become:
- 1000–1300 tokens in English
- much more in some languages
More tokens = higher compute cost.
How Tokenization Works: Step-by-Step
Step 1: Text Cleaning
Raw text often contains:
- HTML
- emojis
- punctuation
- repeated spaces
- encoding noise
Example:
"Hello!!! Welcome 😊"Cleaned:
"Hello Welcome"Step 2: Boundary Detection
Tokenizer identifies splitting boundaries.
Boundaries may be:
- spaces
- punctuation
- special characters
- learned subword rules
Example:
"NLP,is-awesome!"Boundary detection:
["NLP", "is", "awesome"]Step 3: Token Generation
Text is split into units.
Example:
"Deep learning"Becomes:
["Deep", "learning"]Step 4: Vocabulary Mapping
Each token receives a numerical ID.
Example:
"hello" → 245
"world" → 978Final representation:
[245, 978]Types of Tokenization
Comparison Table: Tokenization Methods
| Method | Description | Example | Advantages | Disadvantages |
|---|---|---|---|---|
| Word Tokenization | Splits by words | “AI is smart” → [“AI”,”is”,”smart”] | Simple, intuitive | Fails with unknown words |
| Character Tokenization | Splits into characters | [“A”,”I”] | Handles any input | Long sequences |
| Sentence Tokenization | Splits into sentences | Paragraph → sentences | Useful for summarization | Not semantic enough |
| Subword Tokenization | Splits into meaningful fragments | “playing” → [“play”,”ing”] | Best modern approach | More complex |
| Byte-Level Tokenization | Splits into byte units | Raw encoding chunks | Language agnostic | Hard to interpret |
1. Word Tokenization
Most basic method.
Example:
text = "Natural language processing is powerful"
tokens = text.split()
print(tokens)Output:
['Natural', 'language', 'processing', 'is', 'powerful']Best for:
- basic NLP tasks
- educational demos
- simple preprocessing
Limitations:
- punctuation issues
- unknown words
- vocabulary growth
2. Character Tokenization
Breaks text into individual characters.
Example:
text = "AI"
tokens = list(text)
print(tokens)Output:
['A', 'I']Useful for:
- spelling correction
- OCR
- noisy text handling
Problem:
Sequence becomes too long.
3. Sentence Tokenization
Useful when sentence boundaries matter.
Example:
import nltk
from nltk.tokenize import sent_tokenize
text = "AI is changing the world. NLP powers chatbots."
print(sent_tokenize(text))Output:
[
"AI is changing the world.",
"NLP powers chatbots."
]Applications:
- summarization
- document analysis
- information extraction
4. Subword Tokenization (Most Important)
Modern transformer models rely heavily on this.
Examples:
- BPE (Byte Pair Encoding)
- WordPiece
- SentencePiece
Example:
internationalizationSubword split:
["international", "ization"]Advantages:
- handles rare words
- smaller vocabulary
- better generalization
Used in:
- BERT
- GPT
- translation systems
5. Byte-Level Tokenization
Processes raw bytes rather than language-specific units.
Advantages:
- multilingual compatibility
- handles unusual symbols
- robust for noisy data
Used in some advanced language models.
Popular Tokenization Algorithms
Byte Pair Encoding (BPE)
Starts with characters.
Repeatedly merges frequent pairs.
Example:
Start:
l o w e rMerge:
lo
low
lowerBenefits:
- efficient vocabulary compression
- strong performance in transformers
WordPiece
Used by BERT.
Chooses subwords based on probabilistic usefulness.
Example:
"playing" → ["play", "##ing"]Excellent for contextual models.
SentencePiece
Does not rely on whitespace splitting.
Useful for:
- Japanese
- Chinese
- multilingual NLP
Very flexible.
Tokenization Formulae and Complexity
Token Count Estimation
Approximation:
Example:
1000 characters:
Useful for LLM cost estimation.
Time Complexity
Basic whitespace tokenization:
Where:
- n = text length
Reason:
Single pass through input.
Vocabulary Memory Estimate
Approximation:
Example:
50,000 vocabulary × 768 dimensions
Huge storage implications.
Python Code Examples
NLTK Tokenization
import nltk
from nltk.tokenize import word_tokenize
text = "Tokenization is essential in NLP."
tokens = word_tokenize(text)
print(tokens)Output:
['Tokenization', 'is', 'essential', 'in', 'NLP', '.']Hugging Face BERT Tokenizer
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "Tokenization helps NLP models understand text."
tokens = tokenizer.tokenize(text)
print(tokens)Output:
['token', '##ization', 'helps', 'nl', '##p', 'models', 'understand', 'text']GPT Token Counting Example
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
text = "ChatGPT uses tokens for pricing and processing."
tokens = enc.encode(text)
print(len(tokens))Real-World Industry Use Cases
ChatGPT and Large Language Models
LLMs process tokens, not words.
Impacts:
- pricing
- context window limits
- response speed
- memory usage
Prompt engineering often depends on token efficiency.
BERT Search Engines
Search systems tokenize queries.
Example:
Query:
best budget smartphoneBecomes structured tokens for semantic matching.
Improves relevance.
Machine Translation
Sentence:
"I am learning AI"Tokenizer prepares structured input before translation.
Critical for multilingual systems.
Sentiment Analysis
Example:
"This product is unbelievably good!"Proper tokenization preserves emotional meaning.
Bad tokenization reduces classification accuracy.
OCR and Document Intelligence
Messy scanned text often requires character-level tokenization.
Useful for:
- invoices
- legal documents
- handwritten text
Advantages of Tokenization
| Advantage | Explanation |
|---|---|
| Better NLP performance | Improves understanding |
| Handles unseen words | Especially subword methods |
| Reduces vocabulary size | Efficient training |
| Enables numerical encoding | Required for models |
| Supports multilingual NLP | Byte/subword methods excel |
Disadvantages of Tokenization
| Disadvantage | Explanation |
|---|---|
| Language ambiguity | Word boundaries vary |
| Poor tokenization hurts accuracy | Context may break |
| Increased complexity | Advanced methods harder |
| Longer sequences | Character tokenization issue |
| Cost sensitivity | More tokens = higher API cost |
Common Mistakes to Avoid
Ignoring Language Differences
English tokenization differs from Chinese or Japanese.
Whitespace assumptions fail.
Overusing Word Tokenization
Modern NLP often needs subword methods.
Word-only approaches create many unknown tokens.
Ignoring Punctuation Handling
Example:
"hello!"vs
"hello"Can produce different behavior.
Not Measuring Token Cost
Critical in LLM applications.
Large prompts can become expensive.
Best Practices
Choose Tokenizer by Use Case
Use:
- Word → simple NLP
- Character → noisy text
- Subword → transformers
- Sentence → summarization
Benchmark Token Counts
Always measure token overhead.
Especially for:
- GPT APIs
- embeddings
- RAG systems
Use Pretrained Tokenizers
Avoid building custom tokenizers unless necessary.
Reliable options:
- Hugging Face
- SentencePiece
- tiktoken
Handle Multilingual Text Properly
Use language-aware tokenization.
Global applications require robust segmentation.
Tokenization vs Stemming vs Lemmatization
| Feature | Tokenization | Stemming | Lemmatization |
|---|---|---|---|
| Purpose | Split text | Trim suffixes | Reduce to root meaning |
| Example | “running” → [“running”] | “running” → “run” | “running” → “run” |
| Meaning preserved | Yes | Sometimes no | Usually yes |
| Used first? | Yes | Later preprocessing | Later preprocessing |
Future of Tokenization
Tokenization continues evolving with:
- adaptive tokenization
- multimodal AI token systems
- byte-efficient transformers
- language-independent encoders
Emerging models increasingly optimize token efficiency for scale.
Final Thoughts
Tokenization may appear to be a preprocessing detail, but it fundamentally shapes NLP performance. Every chatbot response, search result, sentiment prediction, and machine translation output depends on how text is split.
Understanding tokenization helps practitioners:
- build better NLP pipelines
- optimize AI costs
- improve model accuracy
- design scalable language applications
If NLP is the brain of language AI, tokenization is the nervous system that carries every signal.