
Introduction: Why “Attention” Changed Everything in AI
Imagine trying to understand a long paragraph in a language you barely know. You don’t process every word equally—you instinctively focus on the most important ones. This human-like ability to prioritize information is exactly what the attention mechanism brought into deep learning, and it fundamentally reshaped how machines process data.
Before attention, models like RNNs and LSTMs struggled with long sequences, often forgetting earlier information. Attention changed that by allowing models to dynamically “look back” and assign importance to different parts of the input. This innovation didn’t just improve performance—it enabled entirely new architectures, including Transformers, which now power systems like machine translation, chatbots, and large language models.
What is the Attention Mechanism in Deep Learning?
The attention mechanism is a technique that allows neural networks to focus on specific parts of the input when producing an output, rather than treating all inputs equally.
In traditional sequence models, information is compressed into a fixed-size vector. This creates a bottleneck, especially for long sequences. Attention removes this limitation by allowing the model to access all hidden states directly and weigh their importance dynamically.
At its core, attention works by computing a weighted sum of input features, where the weights represent the relevance of each input element to the current task.
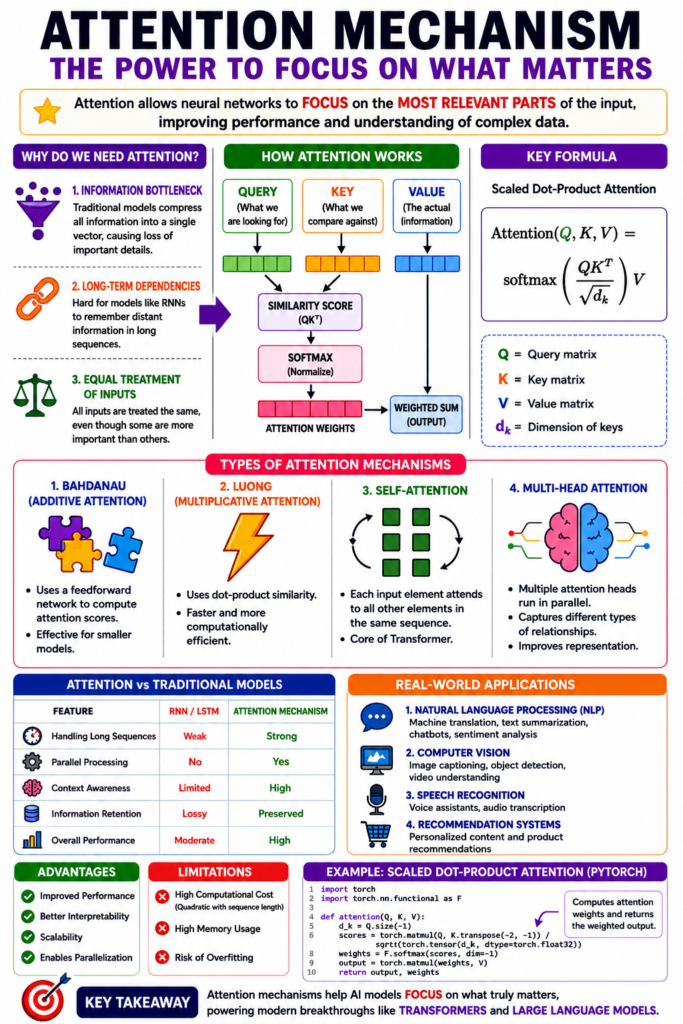
Why Do We Need Attention? The Core Problem It Solves
Before attention, sequence models faced three major challenges:
1. Information Bottleneck
Models like LSTMs compress entire sequences into a single vector, causing loss of important details.
2. Long-Term Dependency Issues
Even with improvements like LSTMs and GRUs, capturing relationships between distant words remains difficult.
3. Equal Treatment of Unequal Inputs
Traditional models do not distinguish between important and irrelevant parts of the input.
Attention solves these by:
- Allowing direct access to all inputs
- Assigning importance weights
- Improving context awareness
How Attention Mechanism Works: Step-by-Step
The attention mechanism revolves around three key components:
- Query (Q): What we are looking for
- Key (K): What we compare against
- Value (V): The actual information
Step 1: Compute Similarity Scores
The model computes how similar the query is to each key.
Step 2: Apply Softmax
The similarity scores are normalized into probabilities.
Step 3: Weighted Sum
The values are combined using the attention weights.
Mathematical Representation
This formula is the backbone of modern attention mechanisms.
Types of Attention Mechanisms
1. Bahdanau Attention (Additive Attention)
- Introduced for machine translation
- Uses a feedforward network to compute attention scores
- Works well for smaller models
2. Luong Attention (Multiplicative Attention)
- Faster than additive attention
- Uses dot-product similarity
- More computationally efficient
3. Self-Attention
- Input attends to itself
- Core component of Transformers
- Enables parallel computation
4. Multi-Head Attention
- Multiple attention layers run in parallel
- Captures different types of relationships
- Improves representation learning
Attention vs Traditional Models: A Clear Comparison
| Feature | RNN/LSTM | Attention Mechanism |
|---|---|---|
| Handling long sequences | Weak | Strong |
| Parallel processing | No | Yes |
| Context awareness | Limited | High |
| Information retention | Lossy | Preserved |
| Performance | Moderate | High |
Role of Attention in Transformer Models
The attention mechanism is the foundation of the Transformer architecture, introduced in the paper “Attention is All You Need.”
Transformers eliminate recurrence entirely and rely solely on attention mechanisms. This allows:
- Faster training through parallelization
- Better handling of long sequences
- Improved scalability
Key Components of Transformers
- Self-attention layers
- Positional encoding
- Feedforward networks
Real-World Applications of Attention Mechanisms
1. Natural Language Processing (NLP)
- Machine translation
- Text summarization
- Chatbots
2. Computer Vision
- Image captioning
- Object detection
3. Speech Recognition
- Voice assistants
- Audio transcription
4. Recommendation Systems
- Personalized content delivery
Code Example: Implementing Attention in Python (PyTorch)
Below is a simplified example of scaled dot-product attention:
import torch
import torch.nn.functional as F
def attention(Q, K, V):
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
weights = F.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output, weights
# Example usage
Q = torch.rand(1, 3, 4)
K = torch.rand(1, 3, 4)
V = torch.rand(1, 3, 4)
output, weights = attention(Q, K, V)
print("Attention Output:\n", output)
print("Attention Weights:\n", weights)This code demonstrates how attention assigns weights and combines values dynamically.
Advantages of Attention Mechanisms
1. Improved Performance
Attention significantly boosts accuracy in NLP and vision tasks.
2. Better Interpretability
Attention weights can be visualized to understand model decisions.
3. Scalability
Works efficiently with large datasets and models.
4. Parallelization
Unlike RNNs, attention enables faster computation.
Limitations of Attention Mechanisms
1. Computational Cost
Attention has quadratic complexity with sequence length.
2. Memory Usage
Large models require significant memory.
3. Overfitting Risk
Powerful models may overfit without proper regularization.
Future of Attention Mechanisms
Attention continues to evolve, with innovations like:
- Sparse attention
- Linear attention
- Efficient Transformers
These aim to reduce computational costs while maintaining performance.
Conclusion: Why Attention is the Backbone of Modern AI
The attention mechanism is not just a feature—it is a paradigm shift in deep learning. By allowing models to focus selectively on important information, attention has unlocked new levels of performance and scalability.
From powering Transformers to enabling large language models, attention has become the foundation of modern AI systems. Understanding it is no longer optional—it is essential for anyone working in machine learning or artificial intelligence.