
Introduction: The Moment AI Stopped “Reading” Sequentially and Started Understanding Context
Artificial Intelligence did not evolve gradually—it leaped forward when transformer models were introduced. Before transformers, most models processed language sequentially, word by word, struggling to retain long-term dependencies and context. This limitation meant that even advanced systems could misunderstand meaning when sentences grew complex or context spanned multiple paragraphs. Then came transformers, a breakthrough architecture that fundamentally changed how machines process information.
Instead of reading text step-by-step, transformers analyze entire sequences at once, identifying relationships between words regardless of their positions. This shift enabled machines to grasp nuance, context, and meaning at an unprecedented level. Today, transformers power nearly every major advancement in AI, from chatbots and translation systems to image generation and code assistants, making them one of the most important innovations in modern computing.
What Are Transformer Models?
Transformer models are a type of deep learning architecture introduced in the 2017 paper “Attention Is All You Need.” Unlike traditional models such as Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks, transformers do not rely on sequential data processing. Instead, they use a mechanism called self-attention to evaluate relationships between all elements in an input simultaneously.
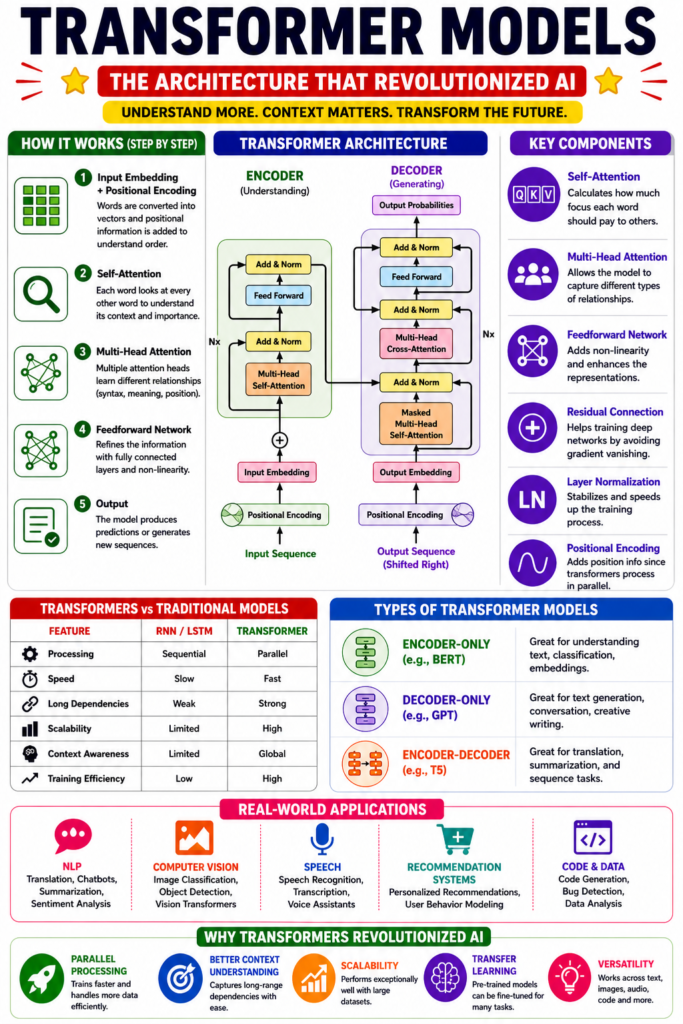
At their core, transformers consist of two main components: an encoder and a decoder. The encoder processes input data and transforms it into a contextual representation, while the decoder generates output based on that representation. This architecture allows transformers to handle tasks like translation, summarization, and question answering with remarkable accuracy and speed.
Why Traditional Models Struggled Before Transformer Models?
Before transformer models, AI models primarily relied on RNNs and LSTMs. These models processed text sequentially, meaning each word depended on the previous one. While this approach worked for short sequences, it introduced several limitations:
- Difficulty capturing long-range dependencies
- Slow training due to sequential computation
- Vanishing or exploding gradient problems
- Limited parallelization
For example, in the sentence:
“The book that the professor who the student admired wrote was fascinating,”
traditional models struggled to connect “book” and “fascinating” because of intervening words.
Transformer models solved this by enabling direct connections between all words in a sentence, regardless of distance.
Core Components of Transformer Architecture
1. Input Embeddings and Positional Encoding
Transformers cannot inherently understand the order of words because they process sequences in parallel. To address this, each input token is converted into a vector (embedding) and combined with positional encoding, which injects information about the token’s position in the sequence.
Without positional encoding, the sentence:
“Dog bites man”
and
“Man bites dog”
would appear identical to the model.
Positional encoding often uses sine and cosine functions:
import numpy as np
def positional_encoding(position, d_model):
angles = np.arange(position)[:, np.newaxis] / np.power(
10000, (2 * (np.arange(d_model)[np.newaxis, :] // 2)) / np.float32(d_model)
)
angles[:, 0::2] = np.sin(angles[:, 0::2])
angles[:, 1::2] = np.cos(angles[:, 1::2])
return anglesThis ensures the model retains sequence order without relying on recurrence.
2. The Core Idea: Attention Mechanism
What is Attention?
Attention allows the model to focus on relevant parts of the input when processing each word. Instead of treating all words equally, the model assigns importance scores to different words based on their relevance.
2.1. Self-Attention Mechanism
Self-attention is the heart of the transformer. It allows each word in a sequence to focus on other relevant words when building its representation. For example:
Sentence: “The bank will not approve the loan because it is risky.”
The word “it” could refer to “bank” or “loan.” Self-attention helps the model correctly associate “it” with “loan” by analyzing context.
This ability to capture relationships across entire sequences is what makes transformers powerful.
Each token is transformed into three vectors:
- Query (Q)
- Key (K)
- Value (V)
The attention score is calculated as:
This equation determines how much attention each word should pay to others in the sequence. For example, in the sentence “The animal didn’t cross the street because it was tired,” the model learns that “it” refers to “animal,” not “street.”
2.2. Multi-Head Attention: Learning Multiple Relationships Simultaneously
Instead of computing a single attention distribution, transformers use multiple attention heads. Each head learns different types of relationships—syntax, semantics, positional relevance, etc.
This enables richer representations:
# Simplified conceptual representation
multi_head_output = concat(head1, head2, head3, ..., headN)By combining multiple perspectives, the model gains a deeper understanding of context.
3. Feedforward Neural Networks
After attention, each token passes through a fully connected feedforward network applied independently:
This step introduces non-linearity and further refines the learned representation.
4. Residual Connections and Layer Normalization
To stabilize training and improve gradient flow, transformers use:
- Residual connections: Add input to output
- Layer normalization: Normalize outputs for consistency
These techniques allow very deep models to train effectively.
Transformer Architecture: Encoder and Decoder
Encoder
The encoder processes input data and generates contextual embeddings. It consists of:
- Self-attention layers
- Feed-forward neural networks
- Normalization and residual connections
Decoder
The decoder generates output using:
- Masked self-attention
- Encoder-decoder attention
- Feed-forward layers
This structure allows the model to generate coherent and contextually accurate outputs.
Comparison: Encoder vs Decoder
Comparison between the two main components:
| Component | Function | Use Case |
|---|---|---|
| Encoder | Processes input sequence | Text classification, embeddings |
| Decoder | Generates output sequence | Text generation, translation |
- Encoder-only models (e.g., BERT): Focus on understanding
- Decoder-only models (e.g., GPT): Focus on generation
- Encoder-decoder models (e.g., T5): Handle both tasks
Step-by-Step Workflow of a Transformer
- Input text is tokenized into words or subwords
- Tokens are converted into embeddings
- Positional encoding is added
- Self-attention calculates relationships
- Multi-head attention refines understanding
- Feed-forward layers process representations
- Decoder generates output
Simple Code Example: Transformer in Python
Below is a simplified example using a transformer model from a popular library:
from transformers import pipeline
# Load a pre-trained model for text generation
generator = pipeline("text-generation", model="gpt2")
# Generate text
result = generator("Artificial intelligence is", max_length=50)
print(result)This code demonstrates how easily transformer models can be applied in real-world applications.
Transformers vs Traditional Models: A Detailed Comparison
| Feature | RNN/LSTM Models | Transformer Models |
|---|---|---|
| Processing Style | Sequential | Parallel |
| Speed | Slow | Fast |
| Long-Range Dependencies | Weak | Strong |
| Scalability | Limited | Highly scalable |
| Context Understanding | Limited | Advanced |
| Training Efficiency | Low | High |
| Use Cases | Speech, basic NLP | NLP, vision, multimodal AI |
Why Transformers Revolutionized AI
1. Parallel Processing
Transformers process entire sequences at once, significantly reducing training time and enabling large-scale models.
2. Superior Context Understanding
By leveraging attention mechanisms, transformers capture deep contextual relationships, making them highly accurate.
3. Scalability
Transformers scale efficiently with more data and parameters, leading to powerful models like GPT and BERT.
4. Versatility Across Domains
Transformers are not limited to text. They are used in:
- Natural Language Processing
- Computer Vision (Vision Transformers)
- Speech Recognition
- Code Generation
Real-World Applications of Transformers
1. Natural Language Processing (NLP)
Transformers power tasks such as sentiment analysis, translation, summarization, and chatbots. Models like GPT and BERT have set new benchmarks.
2. Computer Vision
Vision Transformers (ViTs) treat images as sequences of patches, achieving competitive performance with CNNs.
3. Speech Recognition
Transformers improve transcription accuracy and enable real-time speech processing.
4. Recommendation Systems
They model user behavior sequences for better personalization.
5. Code Generation and Understanding
Transformers can generate, debug, and explain code efficiently.
Simple Transformer Example Using PyTorch
Here is a simplified implementation of a transformer encoder:
import torch
import torch.nn as nn
class SimpleTransformer(nn.Module):
def __init__(self, d_model=512, n_heads=8):
super(SimpleTransformer, self).__init__()
self.attention = nn.MultiheadAttention(d_model, n_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, 2048),
nn.ReLU(),
nn.Linear(2048, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x):
attn_output, _ = self.attention(x, x, x)
x = self.norm1(x + attn_output)
ffn_output = self.ffn(x)
x = self.norm2(x + ffn_output)
return xThis captures the essence of attention + feedforward processing.
Limitations of Transformer Models
Despite their advantages, transformers are not perfect:
- High Computational Cost: Self-attention scales quadratically with sequence length.
- Memory Intensive: Requires large GPU/TPU resources.
- Data Hungry: Needs large datasets for optimal performance.
- Interpretability Issues: Hard to fully understand decision-making.
Researchers are actively working on solutions like sparse attention and efficient transformers.
Future of Transformer Models
Transformers continue to evolve rapidly. Emerging trends include:
- Efficient Transformers: Reducing computational complexity
- Multimodal Models: Combining text, image, and audio understanding
- Smaller, Faster Models: Edge deployment and real-time applications
- General AI Systems: Toward more human-like reasoning
Their adaptability suggests they will remain central to AI development for years to come.
Conclusion: The Backbone of Modern AI
Transformers did not just improve AI—they redefined it. By enabling models to understand context, process data efficiently, and scale to unprecedented levels, transformers have become the backbone of modern artificial intelligence. Whether you are a student, researcher, or professional, understanding transformers is essential to grasp the future of technology. As AI continues to evolve, transformers will remain at the core of breakthroughs that shape how machines understand and interact with the world.