
Introduction: How Generative Pre-Trained Transformers Actually Think, Predict, and Generate Human-Like Text
Artificial Intelligence has moved from being a futuristic concept to becoming a daily productivity companion for students, developers, researchers, businesses, and creators worldwide. From intelligent chatbots and automated coding assistants to AI-powered search engines and content generation tools, one technology sits at the center of this transformation: GPT.
Whether people are asking AI to summarize documents, write code, explain mathematics, or generate marketing campaigns, they are interacting with a system powered by a sophisticated neural network architecture known as the Generative Pre-Trained Transformer. Yet despite its popularity, many users still wonder how GPT models actually work behind the scenes. How does AI predict words so naturally? Why does it generate coherent paragraphs? What makes transformer architecture so powerful compared to older machine learning systems?
Understanding GPT architecture and its autoregressive behavior is essential for anyone studying Artificial Intelligence, Natural Language Processing, Machine Learning, or modern deep learning systems. This article provides a detailed, beginner-friendly, and technically informative explanation of GPT architecture, transformer models, autoregressive prediction, attention mechanisms, training processes, advantages, limitations, and real-world applications.
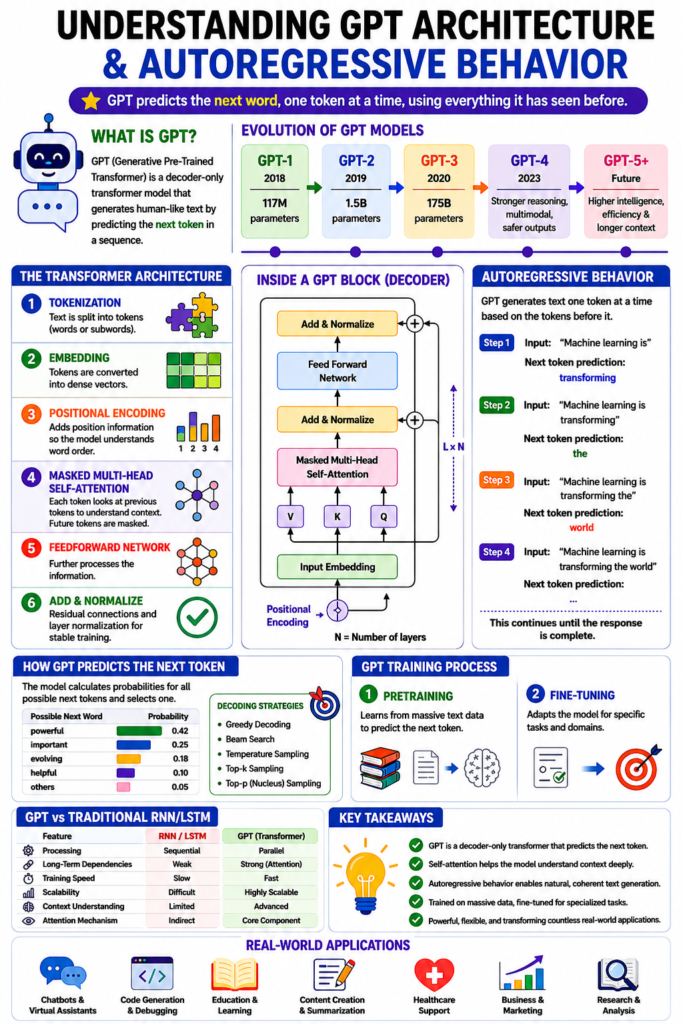
What Is GPT?
GPT stands for Generative Pre-Trained Transformer. It is a family of large language models designed to understand and generate human-like text using deep learning techniques. GPT models are trained on massive amounts of textual data collected from books, websites, articles, documentation, and other language sources. Instead of memorizing exact sentences, GPT learns statistical language patterns, grammar structures, reasoning behaviors, contextual relationships, and semantic meanings between words.
The term “Generative” refers to the model’s ability to generate text. “Pre-Trained” means the model is first trained on enormous datasets before being fine-tuned or used for specific tasks. “Transformer” refers to the neural network architecture introduced in the groundbreaking research paper titled Attention Is All You Need by researchers at Google in 2017.
GPT models are primarily decoder-only transformer architectures. Unlike traditional Natural Language Processing systems that relied heavily on handcrafted rules or feature engineering, GPT learns language representations automatically through large-scale training.
Evolution of GPT Models
The GPT family evolved rapidly over the years, with each version becoming larger, more capable, and more context-aware.
| GPT Version | Key Improvement | Approximate Scale |
|---|---|---|
| GPT-1 | Introduced generative transformer-based language modeling | 117M parameters |
| GPT-2 | Improved text coherence and contextual understanding | 1.5B parameters |
| GPT-3 | Massive scale and few-shot learning capabilities | 175B parameters |
| GPT-4 | Better reasoning, multimodal capabilities, safer responses | Not publicly disclosed |
| GPT-5 Series | Improved reasoning, efficiency, memory, and advanced task handling | Advanced large-scale architecture |
The increase in parameters, training data, and optimization strategies significantly improved the quality of generated responses.
Understanding Transformer Architecture
The transformer architecture is the foundation of GPT models. Traditional neural networks struggled with long-range dependencies in text. Earlier architectures like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) processed words sequentially, making training slow and inefficient for large-scale language tasks.
Transformers solved this problem using a mechanism called self-attention.
Core Components of Transformer Architecture
GPT architecture contains several important building blocks:
1. Tokenization
Before text enters the model, it is converted into smaller units called tokens. Tokens can represent words, subwords, or characters.
Example:
Input Sentence:
"Artificial Intelligence is powerful"
Possible Tokens:
["Artificial", "Intelligence", "is", "powerful"]In practice, GPT often uses subword tokenization methods such as Byte Pair Encoding (BPE).
2. Embedding Layer
Tokens are converted into dense numerical vectors called embeddings. These embeddings capture semantic relationships between words.
For example, the vectors representing “king” and “queen” may appear mathematically related due to contextual similarities learned during training.
Embedding layers transform symbolic text into machine-readable numerical representations.
3. Positional Encoding
Transformers process all tokens simultaneously rather than sequentially. Because of this, they need a way to understand word order.
Positional encoding adds information about token positions.
Example:
| Token | Position |
|---|---|
| Artificial | 1 |
| Intelligence | 2 |
| is | 3 |
| powerful | 4 |
Without positional information, the model would not distinguish between:
- “AI changes industries”
- “Industries change AI”
Word order matters significantly in language understanding.
4. Self-Attention Mechanism
Self-attention is the most revolutionary component of transformers. It allows the model to determine which words are most relevant to one another in a sentence.
For example:
“The robot completed the task because it was efficient.”
The model learns that “it” refers to “robot.”
Self-attention calculates relationships between all tokens simultaneously.
The mechanism uses three vectors:
| Component | Purpose |
|---|---|
| Query (Q) | What information is being searched |
| Key (K) | What information is available |
| Value (V) | Actual contextual information |
The attention formula is:
This formula computes attention scores between words and determines contextual importance.
5. Multi-Head Attention
Instead of using one attention mechanism, transformers use multiple attention heads simultaneously.
Each attention head learns different linguistic relationships such as:
- Grammar
- Context
- Semantic similarity
- Long-range dependencies
- Syntax patterns
This improves the richness of language understanding.
6. Feedforward Neural Networks
After attention processing, the outputs pass through fully connected feedforward neural layers that further refine learned representations.
These layers introduce non-linearity and deeper abstraction capabilities.
7. Layer Normalization and Residual Connections
GPT models use normalization techniques and residual connections to stabilize deep neural network training.
Benefits include:
- Faster convergence
- Reduced vanishing gradients
- Improved training stability
- Better performance in very deep networks
Decoder-Only Architecture in GPT
GPT uses a decoder-only transformer architecture.
Unlike encoder-decoder models such as T5 or traditional translation systems, GPT focuses primarily on predicting the next token in a sequence.
This design makes GPT highly efficient for:
- Text generation
- Conversational AI
- Story writing
- Coding assistance
- Content summarization
- Question answering
The decoder uses masked self-attention to ensure future words remain hidden during training.
What Is Autoregressive Behavior in GPT?
Autoregressive behavior is one of the most important concepts in GPT architecture.
An autoregressive model predicts the next token based on previously generated tokens.
For example:
Input:
“Machine learning is”
The model predicts:
“transforming”
Then the sequence becomes:
“Machine learning is transforming”
The model predicts the next word again:
“modern”
And continues recursively.
This process repeats until the response is complete.
How GPT Predicts the Next Word
GPT computes probabilities for possible next tokens.
Example:
| Possible Next Word | Probability |
|---|---|
| powerful | 0.42 |
| important | 0.25 |
| evolving | 0.18 |
| dangerous | 0.10 |
| random | 0.05 |
The model selects tokens using strategies like:
- Greedy decoding
- Beam search
- Temperature sampling
- Top-k sampling
- Top-p nucleus sampling
These methods affect creativity and diversity in generated text.
Why Autoregressive Models Are Powerful
Autoregressive generation enables GPT to produce highly coherent and context-aware outputs.
Advantages include:
Context Preservation
The model continuously references previously generated words, helping maintain consistency.
Natural Sentence Formation
Language naturally flows from previous context, making generated text more human-like.
Scalability
Autoregressive training works efficiently on massive datasets.
Flexibility
The same architecture supports:
- Chatbots
- Translation
- Coding
- Content generation
- Summarization
- Reasoning tasks
Training Process of GPT Models
GPT training typically occurs in two major stages.
1. Pretraining
During pretraining, the model learns language patterns from massive datasets.
The training objective is:
Predict the next token.
Example:
Input:
“Deep learning models are”
Target:
“powerful”
This process repeats billions of times across enormous datasets.
The optimization process minimizes prediction error using gradient descent and backpropagation.
2. Fine-Tuning
After pretraining, models may undergo fine-tuning for specialized tasks such as:
- Customer support
- Healthcare assistance
- Legal analysis
- Coding support
- Educational tutoring
Fine-tuning aligns the model with specific domains and desired behaviors.
Understanding Context Windows
GPT models operate within a context window.
A context window defines how many tokens the model can process simultaneously.
| Model Type | Approximate Context Window |
|---|---|
| Early GPT Models | Few thousand tokens |
| Advanced GPT Models | Tens or hundreds of thousands of tokens |
Larger context windows improve:
- Long document understanding
- Memory retention
- Conversation continuity
- Multi-step reasoning
Example of Simple Autoregressive Text Generation
Here is a simplified Python example demonstrating next-word prediction logic:
text = "Artificial Intelligence is"
while not end_of_sentence:
next_word = predict_next_word(text)
text += " " + next_word
print(text)Although real GPT systems are vastly more complex, the core principle remains similar.
GPT vs Traditional Neural Networks
| Feature | Traditional RNN/LSTM | GPT Transformer |
|---|---|---|
| Processing Style | Sequential | Parallel |
| Long-Term Memory | Limited | Strong |
| Training Speed | Slower | Faster |
| Scalability | Difficult | Highly scalable |
| Attention Mechanism | Weak/Indirect | Core component |
| Context Understanding | Moderate | Advanced |
| Parallel Computation | Limited | Efficient |
Transformers dramatically improved NLP performance compared to earlier architectures.
Real-World Applications of GPT
GPT models are transforming multiple industries.
Education
Students use GPT for:
- Concept explanations
- Research summaries
- Coding help
- Writing assistance
Software Development
Developers use GPT for:
- Code generation
- Debugging
- Documentation
- Automation
Healthcare
AI systems assist with:
- Medical documentation
- Clinical summarization
- Healthcare chatbots
Business and Marketing
Organizations use GPT for:
- Customer support
- Content creation
- Market analysis
- Personalized communication
Research and Data Analysis
Researchers leverage GPT for:
- Literature reviews
- Data interpretation
- Knowledge extraction
Limitations of GPT Architecture
Despite its capabilities, GPT has important limitations.
Hallucination Problems
GPT may generate incorrect or fabricated information confidently.
Lack of True Understanding
The model predicts patterns statistically rather than possessing genuine consciousness or reasoning.
High Computational Cost
Training large GPT models requires enormous computational resources.
Bias in Training Data
Models may inherit societal biases present in internet-scale datasets.
Context Limitations
Even advanced models have finite context windows.
Future of GPT and Transformer Models
Future AI systems are expected to improve in:
- Reasoning abilities
- Memory persistence
- Energy efficiency
- Multimodal understanding
- Scientific problem-solving
- Personalized AI assistance
Researchers are also exploring hybrid architectures combining transformers with symbolic reasoning and external memory systems.
Why Understanding GPT Architecture Matters
Understanding GPT architecture is increasingly important for:
- AI engineers
- Data scientists
- Students
- Researchers
- Business leaders
- Developers
As AI becomes integrated into education, healthcare, finance, governance, and software systems, foundational knowledge of transformer models and autoregressive behavior becomes a valuable technical skill.
Rather than treating AI as a mysterious black box, understanding its internal mechanisms enables better development, ethical deployment, and informed decision-making.
Conclusion
GPT architecture represents one of the most significant breakthroughs in Artificial Intelligence and Natural Language Processing. By combining transformer-based attention mechanisms with autoregressive next-token prediction, GPT models achieve remarkable capabilities in understanding and generating human-like text. The transformer architecture solved major limitations of earlier neural networks, enabling parallel computation, long-range contextual understanding, and large-scale language learning. Autoregressive behavior allows GPT to generate coherent responses step-by-step by continuously predicting the most probable next token based on prior context.
While these models remain imperfect and computationally expensive, their impact on education, software engineering, healthcare, business, and research is already reshaping modern digital interaction. As transformer technology continues evolving, understanding GPT architecture will remain essential for anyone interested in the future of AI, machine learning, and intelligent systems.